Compositional Software Design
- Why Compositional Software Design?
- Design Thinking vs. Prepackaged Solutions
- Composition as a Common Theme
- Composability Can Increase Reusability and Testability
- The 4 Aspects of Compositional Design
- The 3 Principles of Compositional Design
- Why, When and How to Split Your Code
- Compositional Design Principles
- Narrowing Responsibility
- Widen the Applicability
- Reduce Applicability Effort
Jakob Jenkov |
Compositional Software Design is the name I have given my personal software design style which focuses on designing your codebase for composability. You design for composability to increase the reusability and testability of your codebase. Designing for composability also tends to reduce the size of your codebase.
You design for composability by decomposing your codebase into smaller units which can be composed together to form composite solutions to a variety of problems. These smaller units, also sometimes referred to as components, become the low-level building blocks of your application, service, API or whatever software you are developing. Of course, you may need some "glue code" in between the units to wire them together to form the final solution.
You only design for composability in the situations where you actually benefit from the composability. In some situations you might not need the reusability of certain pieces of code, so you abstain from decomposing that code. Similarly, in some situations achieving high performance may be more important than achieving reusablity, so you design for performance (e.g. using Data Oriented Programming) rather than for composability in that situation.
Sometimes I may refer to Compositional Software Design simply as Compositional Design because it is shorter to write. I am referring to the same concept, however.
Why Compositional Software Design?
I started looking into what eventually became compositional software design in 2023 - and have since then been working on refining the ideas to be more concrete and more easily applicable. Before diving into the finer details of compositional software design, I want to give you a bit of history of where I got the ideas from.
Reusability is Not a New Idea
Let me first make it clear that in 2023 there was nothing new about breaking your codebase into reusable units. This has been a good practice for as long as I can remember (I started programming in 1987) - and probably long before I remember too.
Composition is Not a New Idea
Composition is not a new idea either. Using composition as a way to structure your classes is a technique that is almost as old as object-oriented programming. However, the old-school OOP thinking on composition is mostly concerned with whether you should use composition or inheritance. Not so much with how you actually design your code to make it more composable.
What is New Then?
What is new in compositional software design is the focus on studying how to increase the composability of your code. The more composable your code is, the more reusable and testable it tends to become - and the faster you can typically add new functionality to your software.
What Triggered These Ideas?
The reason I started looking into this is, that I started seeing a lot of criticism of object-oriented programming, and claims that either functional programming or other design techniques were better. However, I felt this criticism of object-oriented programming was missing something.
The criticism often referred to object-oriented programming as described by the classic academic object-oriented-programming theory. However, I do not feel that the classic object-oriented programming theory is an accurate representation of how object-oriented programming is done in reality anymore - and it probably has not been since the mid 2000's. Classic object-oriented programming theory does not mention design patterns or dependency injection. Nor does it mention designing for replaceability or removeability.
The more I looked into the underlying ideas behind object-oriented-programming and its alternatives, the more I found them to attempt to achieve the same goals. I find that object-oriented-programming and functional programming are actually quite similar in many respects, rather than two completely different paradigms.
I also found, that strict adherence to design doctrines is not always a good idea. Design doctrines and dogma should be considered to be guidelines rather than hard rules. Deviate from them whenever it makes sense to do so (but be ready to explain why it makes sense to deviate in that specific situation). But this is a ifferent discussion which I am talking more about in my tutorial about Conscious Software Design.
Design Thinking vs. Prepackaged Solutions
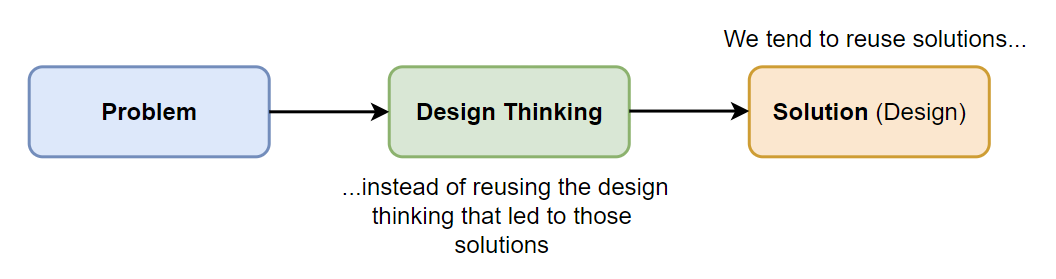
In general, whenever we have a software problem we apply some kind of design thinking which produces some kind of solution. We often refer to this solution as a "design". This process is illustrated here (a bit simplified):

There is no problem with this simple process by itself.
The problem is, that we tend tro try to reuse the resulting solutions rather than reusing the design thinking that went into producing the solution. We tend to name and memorize the different solutions - and later to attempt to reapply those same solutions. We think in terms of "legs" and "wheels" rather than "transportability across different surfaces".
The growing catalogue of design patterns is a great example of this. We think in terms of "factories", "abstract factories", "builders", "service locators" or "dependency injection" rather than "implementation replaceability".
If we try to apply the same solution in two different situations, we are essentially trying to make our problem fit the solution, rather than making the solution fit our problem.
What I would like to do instead is - not to reuse the design solutions - but to reuse the design thinking that led to those solutions. This should help us produce solutions that are specifically designed for each specific situation.
Put differently, I believe we should focus on design thinking rather than design patterns. This also means focusing on appropriate practices rather than best practices.
Focusing on the design thinking rather than the resulting solutions - is what I am trying to do with compositional software design.

Composition as a Common Theme
As mentioned earlier, I feel that OOP and its alternatives (e.g. FP) are trying to solve the same problem (or very similar problems at least). When I talk about OOP I include ideas such as design patterns, dependency injection, SOLID, hexagonal architecture etc. So what do these ideas have in common?
The main theme I see run through all of these ideas is composition. Various ways of composing objects or functions together to solve certain problems or achieve certain possibilities.
Thus - I started looking for ways to design for composability. The results are the principles outlined in this article about compositional software design.
Note, that Data Oriented Programming is an outlier here. The underlying principle of Data Oriented Programming is to design your code for efficient access to, and iteration of, larger amounts of data. The goal is performance, and it is achieved by designing your code to align more with how the underlying hardware works. In other words, data oriented programming designs for performance - not composability.
You can combine Data Oriented Programming and Compositional Software Design if you want to - using each style where it makes sense in your codebase, but the styles do not share a common underlying theme.
Composability Can Increase Reusability and Testability
The main benefit of composability is that it increases the potential for reuse. With reuse you get fewer bugs and faster development speed. Sometimes you get a bit more readability too - but that depends on the design of the components. It is certainly possible to design components in ways that makes them less readable.
Another possible benefit of designing for composability is, that your components tend to become easier to unit test. Or - at least you can design them to be easier to test using the techniques described in this tutorial.
The 4 Aspects of Compositional Design
If you imagine that you start with a single, bigger unit (class or function), and you want to re-design that unit by splitting it into multiple units, there are 4 core aspects that we look at in compositional software design:
- Dividing responsibility of big unit among smaller units.
- Connecting the units.
- Improving interfaces of units.
- Designing support units to make the core units easier to use.
I will go into a bit more detail with these 4 aspects in the following sections.
Imagine that you have a single unit that you want to split up into smaller units, as illustrated here:

Then the 4 aspects of compositional design that we are focused on, look like this:
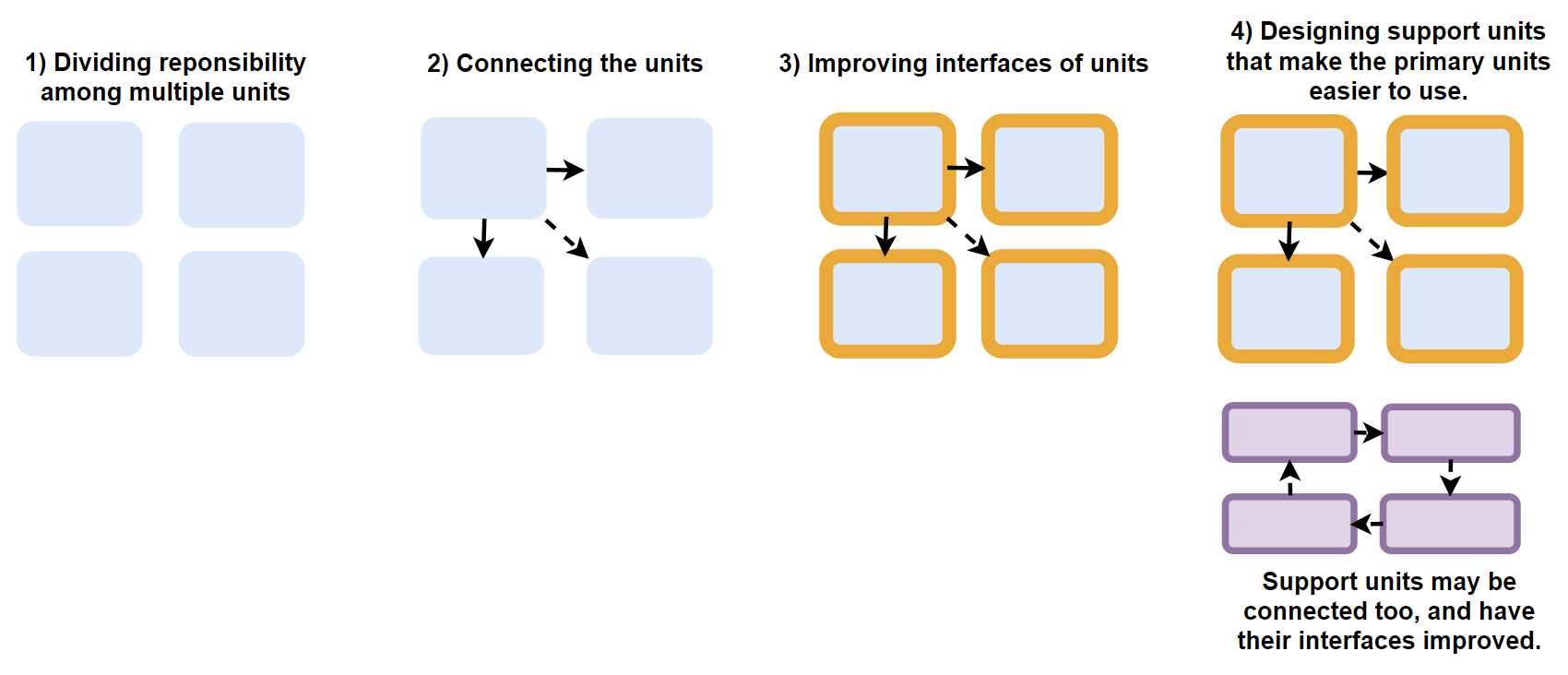
First, we focus on how to divide the responsibility of the big unit among the new, smaller units that we are splitting the big unit into.
Second, we focus on connecting the new units. By "connecting" I mean how they reference each other. There are several ways one unit (class or function) could reference another unit in your code base. I will get back to that later in this article.
Third, we focus on improving the interfaces of the resulting units, so they can be used in more use cases than just the ones we created the units for today (be careful not to overdo it!) .
Fourth, we may add support units that make it easier to use the primary units we just created. A support unit could be a factory or a builder that makes it easier to compose a fully working composition of the new units - or a facade that gives you a simpler interface to the new units for common use cases.
The 3 Principles of Compositional Design
We address the 4 aspects of compositional software via 3 core principles:
- Narrow the responsibility
- Widen the applicability
- Make the units easier to use
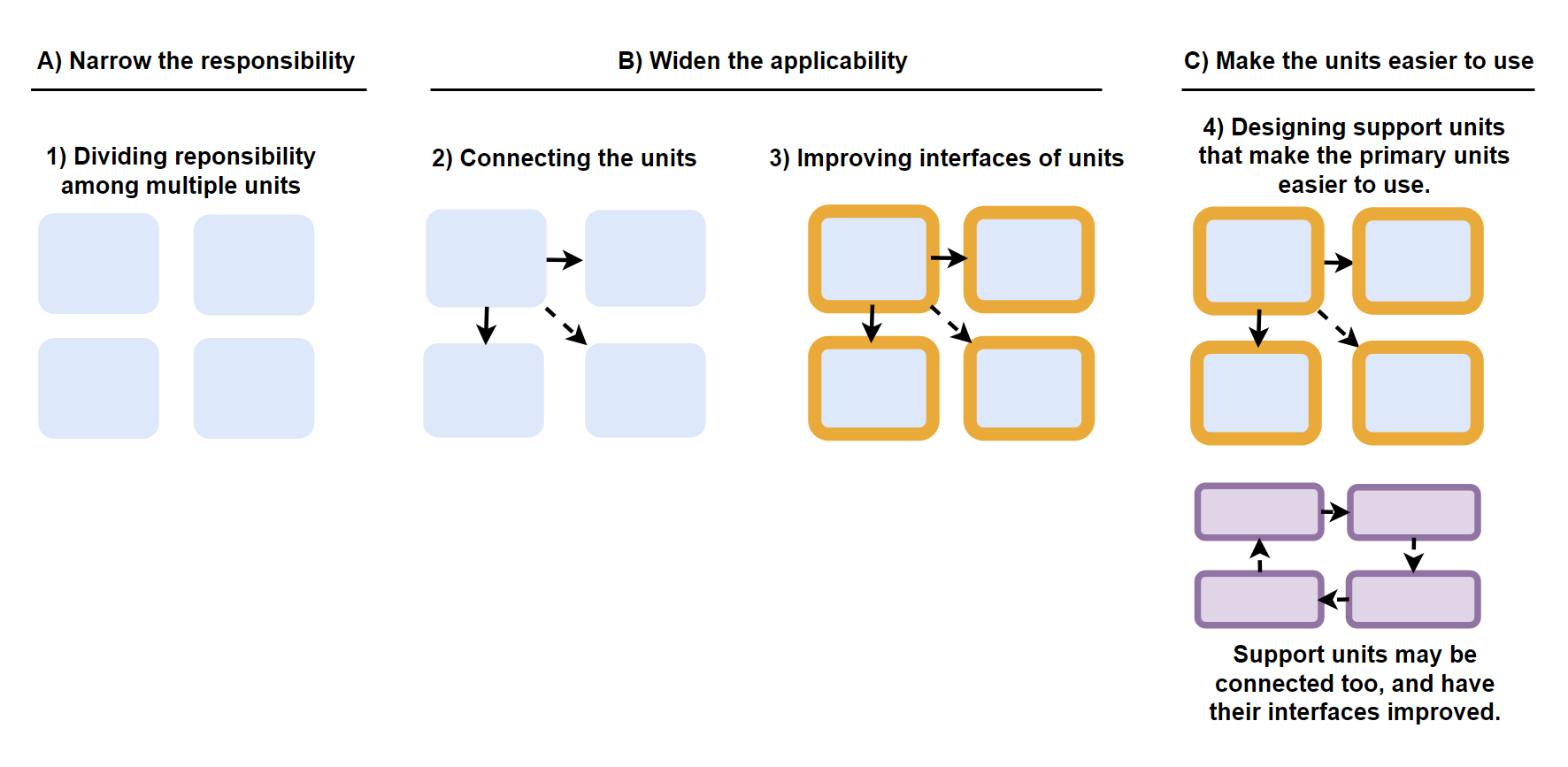
These 3 core principles map to the 4 core aspects, like this:
| Principle | Aspect |
|---|---|
| Narrow the responsibility | Divide the responsibility among multiple units. |
| Widen the applicability | Connect the units. |
| Improve the interfaces of units. | |
| Make the units easier to use | Design support units. |
In other words, if you remember the 3 core principles, you will have a good chance of addressing the 4 core aspects of compositional software design. Let me explain in a bit more detail:
"Narrowing the responsibility of each unit" - is how we "divide the responsibility of a unit among multiple units".
"Widening the applicability of each unit" - is how we "connect the units" and "improve the interfaces of units".
"Make the units easier to use" - is how we "design support units".
This mapping is also illustrated here:
Why, When and How to Split Your Code
As mentioned in the beginning, the focus in compositional software design is on why, when and how we split a unit into multiple units.
Why: We typically split a unit of code into multiple units to achieve increased reusability, or increased testability.
When: We don't have to split a unit into multiple units until we will actually achieve a benefit from making that split. In other words, not until we actually achieve increased reuse - or increased testing, meaning some of the code will be actually be reused, or we will actually write a more thorough test for the new units than we already have.
How: Splitting up a unit into multiple units typically follows the following steps:
- Identify a responsibility that you want to extract - because we want to be able to reuse, replace, remove or
otherwise amend it.
- Make the split. Extract the code we have identified for extraction.
- Improve reusability of all units resulting from the split - not just the extracted unit. We will see ways to do that later in this tutorial.
The three steps under how to split up a unit into multiple units are correct - but not very specific. They could be more concrete - so it was easier to know what do to in practice.
To alleviate this lack of specificity and concreteness - Compositional Software Design has three reasonably concrete core principles, as explained in the next section.
Compositional Design Principles
Compositional Design has three core design principles:
- Narrow Responsibility
- Widen Applicability
- Reduce Use Effort
Narrowing responsibility means splitting a unit of code into multiple units, each with a narrower responsibility than the unit that was split.
Widen applicability means that you change one (or more) units so they can be used in a wider set of use cases. Widening the applicability of a unit thus increases it reusability. This is typically done by changing its functionality subtly as well as changing its interface.
Reduce use effort means that you reduce the effort required to use one or more units. You make the units easier to use, in other words. This is typically done by modifying its interface (e.g. via overloaded methods) or by adding extra supporting components (such as factories or builders etc.).
Each of these core principles of compositional software design relates to the "Why, When and How to Split Your Code" principles like this:
| Principle | Relates To |
|---|---|
| Narrow Responsibility | Why + When + How (1 + 2) |
| Widen Applicability | How (2 + 3) |
| Reduce Use Effort | How (3) |
I will explore each principle in more detail in the following sections.
Narrowing Responsibility
Narrowing the responsibility of a unit of code is done by splitting the responsibility of a unit into multiple units. Typically, one or more units are extracted from the original unit. A unit in this context can be either a class, method, function, data structure - or even an interface.
Narrowing the responsibility of a unit - into multiple units with narrower responsibilities - requres two steps:
- Splitting the responsibility
- Connecting the responsibilities
When narrowing responsibility it is important to remember to think about the reusability and testability of both the new extracted unit as well as what remains of the old unit. A good way to do that, is to change how we identify responsibility to extract. Let me elaborate a bit more on that:
Traditionally we have been told to look for responsibility (code) that can be reused - and then to extract and reuse that responsibility. I believe we should expand that thinking to look for responsibility (code) to:
- Reuse
- Replace
- Remove
- Ammend
When your mind is tuned into looking for code to reuse, your focus is very much on the code you are extracting for reuse.
However, once you start thinking about identifying responsibility (code) to replace, remove or ammend the focus shifts from the extracted code to the unit you extract from. It is the reusability of the unit you extract from that becomes your focus. It has to be reusable with different implementations of the responsibility that you extract.
In order to be able to replace one responsibility with another, you must have a configurable reference to that responsibility. It is this reference that "connects" the responsibilities after the split. Depending on how you model this reference - this connection between the responsibilities - you achieve different levels of composability. I will explore that in more detail in the following sections.
Static, Dynamic and Polymorphic Composability
There are three levels of composability that you can design for in your code:
- Static Composability
- Dynamic Composability
- Polymorphic Composability
I will explain the difference between each of these composability levels in the following sections.
Static Composability
Static composability means that a function A that uses another function B - does so by referencing B from within the code of A in a static fashion. In other words, the reference to B cannot be changed at runtime. It is static (hardcoded). Here is an example of static composability:
public void a() {
String result = b();
}
private String b() {
return "" + System.currentTimeMillis();
}
The call to b() from inside of a() cannot be changed at runtime.
It is static. Thus, the composition of a() and b() is static.
Dynamic Composability
Dynamic composability means that components are designed so their composition is decided at runtime. This is typically done via dependency injection - via constructor injection. However, once a dynamic composition has been made, it cannot be recomposed. It can be dynamically composed, but not re-composed at runtime. Here is an example of dynamic composability:
public class ComponentA {
private ComponentB componentB = null;
public void ComponentA(ComponentB componentB) {
this.componentB = componentB;
}
public void a() {
this.componentB.b();
}
}
public class ComponentB{
public String b() {
return "" + System.currentTimeMillis();
}
}
ComponentB componentB =
new ComponentB();
ComponentA componentA =
new ComponentA(componentB);
componentA.a();
Notice how it is possible to compose a ComponentA and a ComponentB together at runtime, but once they are wired together, you cannot re-compose them.
Polymorphic Composability
Polymorphic composability means that components are designed to be both composed and re-composed at runtime. This is typically achieved using dependency injection via setter injection, or by passing a dependency as a parameter to a method or function - using call-time composition.
Here is first an example of polymorphic composability via setter injection.
public class ComponentA {
private ComponentB componentB = null;
public void ComponentA() {}
public void setComponentB(ComponentB componentB) {
this.componentB = componentB;
}
public void a() {
this.componentB.b();
}
}
Notice how the constructor injection from the example in the dynamic composability section has simply been replaced with setter injection. Everything else is the same. However, now a ComponentA instance could have it's ComponentB instance replaced at runtime.
Here is an example of polymorphic composability via call-time composition - meaning where the dependency (ComponentB) is passed in as parameter to the method that uses it:
public class ComponentA {
public void ComponentA() {}
public void a(ComponentB componentB) {
componentB.b();
}
}
Using this design you can re-compose ComponentA with an instance of ComponentB every time you call
the a() method. This gives flexibility, but also makes the code a bit more verbose,
as you will have to declare the composition every single time you call a() .
If you need to call a() in more than place in your code with the same ComponentB instance,
this will make your code a bit more repetitive to look at.
Widen the Applicability
Widening the applicability of a component is typically done by changing or expanding its interface to be able to accommodate more use cases.
The reason we want our components to accommodate more use cases is because it increases the reusability of that component - and reusability is what compositional software design is all about.
To make it easier to understand what I mean by widening the applicability of a component - let us look at an example. The following method is capable of processing an array of bytes. It is not so important what the processing consists of. It is the interface of the component (the signature of the method) that is interesting:
class DataProcessor{
Object process(byte[] bytes){ ... }
}
The process() method can take a byte array, and do some kind of processing of the bytes in that array.
However, this method is designed to work on all bytes of the byte array. What if you only wanted to process a part of the byte array? You cannot tell the process() method what part of the array to process, as the method does not have any parameters to specify that.
Here is a change in the methods signature that widens its applicability:
class DataProcessor{
Object process(byte[] bytes, int offset, int length){ ... }
}
As you can see, now it is possible to specify from which offset and how many bytes forward in the byte array you want the process() method to process. You can either process all of the byte array, or some of it.
Exactly how you widen the applicability of a component depends on the function and interface of that component. The above was just an example.
Reduce Applicability Effort
Reducing the applicability effort of a component means making the component easier to use. We do so by changing its interface, or adding supporting components (such as factories or builders) that make it easier to create (compose) the component - and easier to use it too.
I will use the example from the previous section about "widening the applicability" to show an example of how you could make a component easier to use (meaning requiring less effort to use).
In the example in the previous section I changed the method signature from taking just a byte array to also take an offset and a length parameter. This enabled us to process both the whole byte array, or just a subset of the byte array.
However, what if you actually want to process the entire byte array? With the changed method signature you still have to provide the offset and length parameters, resulting in a bit more "effort" to use the method. Here is how calling it would look:
DataProcessor dataProcessor = new DataProcessor(); byte[] data = ... //get data from somewhere. dataProcessor.process(data, 0, data.length);
To make it a bit easier to call the DataProcessor's process() method we can add an overloaded version of the process() method that only takes a byte array as parameter. Here is how the DataProcessor class (only it's interface) would look:
class DataProcessor{
Object process(byte[] bytes){ ... }
Object process(byte[] bytes, int offset, int length){ ... }
}
Now, if you want to process the whole byte array, you can just call the version of the process() method that only takes the byte array.
You could add more methods to make the component easier to use in more situations, just like we just did. For instance, you could add a processFrom(byte[] bytes, int offset) method, and a processTo(byte[] bytes, int length) method.
| Tweet | |
Jakob Jenkov | |











