Structural Software Design
Jakob Jenkov |
Structural software design is my term for the part of the software design that is concerned with the internal structure of the software. The division of the code into smaller components, and the control below between them, in other words.
Structural Software Design Tutorial Video
If you prefer video, I have a video version of this tutorial here: Structural Software Design

Core Elements of Structural Software Design
The core elements of structural software design are what makes up the core of the structure of your software. These elements are:
- The decomposition of the software into smaller components.
- The interface of these smaller components.
- The control flow between the components.
I will write a bit more about each of these elements in the following sections.
Software Decomposition
Software decomposition means breaking the software into smaller components. Breaking software into smaller components can have a set of advantages - and also a few disadvantages. There are several different philosophies about how to decompose software - so I will not get into that here. I will get into that in separate articles.
Component Interfaces
The interfaces between the components you have decomposed your software into - has a big impact on how easy the components are to compose into larger structures, and also on how easy the components are to use. Paying attention to component interfaces is therefore beneficial. This is where design patterns and similar techniques come into play.

Control Flow
The direction of the control flow between the components in your software is another central structural software design aspect. Should component A call B, or should B call A, or should you have a C that first calls A and then calls B ? Different control flows result from different designs, and different desired control flows may result in different designs too.
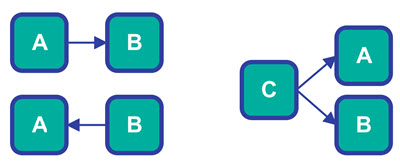
The above diagram shows 3 different abstract control flow options (3 different design options). To make the examples a bit more concrete, let us put some concrete responsibilities (functionalities) on the components in each of the examples.
In the first case, where A calls B - imagine that:
- A is a File Loader
- B is a Data Processor
You create an A (File Loader) and call its load() method, and passes a B (Data processor) to its load() method. Here is a rough sketch of that:
A a = new A();
byte[] result = a.load("filepath", new B());
A will load the file located at "filepath" and pass the bytes on to B which processes them and returns a result (byte array) to A - which A then returns to whatever component that calls a.load().
In the second case, where B calls A - imagine that:
- A is a Data Source
- B is a Data Processor
If A is to be an abstract Data Source, there would probably exist an interface named DataSource with one or more implementations of that interface which can read data from different sources (file system, HTTP etc.). Imagine that the class A is an implementation of this DataSource interface.
To have B process data you would call its process() method, passing a DataSource implementation to this method as parameter. Here is a rough sketch of that:
B b = new B();
byte[] result = b.process( new A("filepath") );
B calls A to get A to load the data (byte array) - which B then processes and returns the result (also a byte array) to whatever component that calls B.
In the third case, where C calls first A then B - imagine that:
- A is a Data Source
- B is a Data Processor
- C is a Data Processing Coordinator
To have your data processed, you call C's process() method with an instance of A and B. Here is a rough sketch of that:
C c = new C();
byte[] result = c.process( new A("filepath"), new B() );
If you wanted to use C with another DataSource implementation, e.g. A2, it could look like this:
byte[] result = c.process( new A2("URL"), new B() );
Control Flow Affects Decomposition and Interfaces
As you might have realized by now, control flow affects both the decomposition of your code base and the interfaces of the components you decompose into. In the example shown in the diagram above, each of the possible control flows will require different interfaces and responsibilities of the components.
In the first control flow, A needs to know about B - meaning the interface of A probably needs to know about B somehow. But the interface of B does not need to know about A.
In the second control flow, B needs to know about A - meaning the interface of B probably needs to know about A somehow. But the interface of A does not need to know about B.
In the third control flow, C needs to know about both A and B - meaning the interface of C probably needs to know about A and B somehow. But the interface of A does not need to know about B or C, and the interface of B does not need to know about A or C. Note too, that we pass the file path to A via its constructor instead of via its load() method.
Structural Design is Derived From Design Goals
Exactly how you decompose your code into components and how you design their interfaces and the control flow between them depends on what software design goals you are trying to achieve. Design goals such as reusability, testability etc. play a role during the decomposition.
There are several design philosophies that talk about how you can structure your code. Functional programming, design patterns, SOLID, hexagonal architecture etc. all have ideas about that. I have some simple yet quite useful ideas too - which I call compositional design. I will get into more detail about functional programming, design patterns, SOLID, hexagonal architecture, compositional design etc. in a separate articles.
| Tweet | |
Jakob Jenkov | |











