Java: Iterating Streams Using Buffers
Jakob Jenkov |
Sometimes when iterating a stream of bytes, it is not enough to look at each byte separately. You may need to have at least N next bytes (e.g. 1024 bytes) available from the stream in a buffer at all times. For instance, if you are parsing a programming language you may need to move forth and back in the data obtained from the stream - read ahead and backtrack in other words. To be able to move forth and back in the stream data, you may need to keep the next e.g. 1024 or 2048 (or more) bytes available in a buffer.
To solve this problem I will develop a RollingBufferInputStream class which keeps at least N bytes
available in a buffer. The bytes are read from another InputStream. At the end of this
text there is a full code listing of RollingBufferInputStream which you can copy, so yo don't have
to develop this yourself.
Here is a simple illustration of the problem described above:
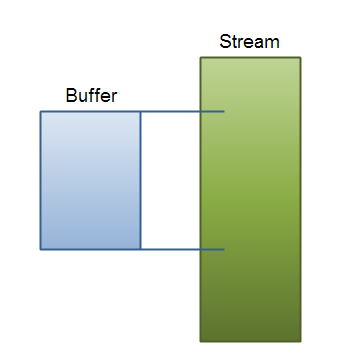 |
| Iterating a stream while keepin N bytes available from it in a buffer. |
As you progress through the stream, you basically read data into the end of the buffer, and take data out of the top of the buffer. Actually, you don't take data out of the top of the buffer. You just move up the data later down the buffer. Then you read new data from the stream into the end of the buffer.
Basically you carry out two operations:
- Copy data from the bottom to the top of the buffer. This is also known as compacting the buffer.
- Read new data into the buffer, after any existing data that is already read into the buffer. I refer to this action as filling data in the buffer. If no data is already in the buffer, it is filled from the top.
Buffer Size
The first issue to address is the size of the buffer used to keep data in. If you need to have access to at least 1024 bytes, you need a buffer of at least 1024 bytes too. In other words, you have two properties to take into consideration:
- Block Size: The number of bytes you need access to.
- Buffer Size: The size of the buffer. Must be at least equal to block size.
Buffer Size = Block Size
If the buffer has exactly block size bytes, then every time you have checked the buffer
from byte 0, for what you are looking for, you need to compact the buffer. Either because you found
what you were looking for, from index 0, or because you did not find what you were looking for, and
need to look from index 1 and block size bytes ahead.
If we assume that you can only skip 1 byte ahead every time you do not find what you are looking for,
then you need to copy the block size - 1 bytes in the remainder of the buffer, to the
top of the buffer, before looking again, and then read 1 byte into the last cell of the buffer.
For instance, if the block size and buffer size are both 1024 bytes, then every time you did not find what you were looking from index 0, you need to copy the 1023 last bytes of the buffer up to index 0, and read a byte into the bottom of the buffer. This means copying 1023 bytes for every byte processed in the buffer. This is very expensive.
Buffer Size > Block Size
Instead of compacting the buffer for each and every byte read from the top of it, you can make the buffer
size larger than the block size. If you make the the buffer size equal to block size + 1, then
you would only need to compact the buffer for every two bytes read. If you make the buffer size equal to
block size * 2 then you will only have to compact the buffer every block size
bytes.
For instance, if block size is 1024 and buffer size is 2048, then you can process 1024 bytes down the buffer, until there is less than 1024 bytes left in the buffer. This means only 1 compaction for every 1024 bytes processed. This yields a much better performance than 1 compacttion per 1 byte processed.
Since compaction of the buffer can be expensive, the fewer compactions of the buffer that are necessary,
the better. Therefore, the larger the buffer is, the better. Of course you have to weigh the size of the
buffer against what else you need memory for in your application. An application that starts swapping
on the hard disk because it consumes too much memory, loses a lot of performance too. Often, a buffer size of
2 to 4 times block size will be fine.
Here is an illustration of block size, buffer size and stream iteration principle:
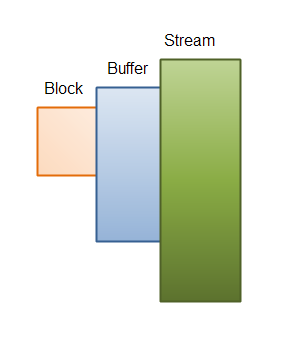 |
| A buffer size which is larger than the needed block size. |
The RollingBufferInputStream
The RollingBufferInputStream class which I have developed, can be used to iterate an InputStream
while at the same time making sure there is always block size bytes available in the buffer. Unless
the end-of-stream is reached, of course.
Note: Even if the class is called RollingBufferInputStream, it is not an InputStream
subclass. This makes sense, since you will not be using any of the traditional methods of an InputStream
when working with a RollingBufferInputStream. You will only be working with its special methods,
and you will access the data from the stream via its internal buffer.
Using the RollingBufferInputStream
Before I show you how the RollingBufferInputStream is implemented, I will first show you how
to use it. Then you will probably better understand its implementation.
int blockSize = 1024;
byte[] buffer = new byte[blockSize * 4];
RollingBufferInputStream bufferInput =
new RollingBufferInputStream(sourceInputStream, buffer);
while(bufferInput.hasAvailableBytes(blockSize)){
boolean matchFound = lookForMatch(
bufferInput.getBuffer(),
bufferInput.getStart(),
bufferInput.getEnd());
if(matchFound){
localFileSource.moveStart(this.blockSize);
} else {
localFileSource.moveStart(1);
}
}
First you ask if the buffer has N available bytes, by calling hasAvailableBytes().
If the buffer does not contain N bytes, this method will internally attempt to fill the buffer. After attempting
this, the method will then check if the buffer now contains N bytes. If it does, it returns true.
Else it returns false.
Second, you look for a match in the buffer. The RollingBufferInputStream contains methods
to access the buffer, and to know how many bytes are available in it, and where the current
start index is.
Third, you increase the start index in the buffer by the appropriate value. If a match was found, this example skips over the whole block. If you were parsing a language, you might just skip to the end of the found statement. If no match was found, you move the start index by 1, or whatever value is appropriate, to skip ahead and start searching from the next index.
RollingBufferInputStream Implementation Outline
Here is the first outline of the RollingBufferInputStream class. Some of the code has been taken out
here for clarity. A full code listing can be found at the end of this text. This outline mostly
serves to show you the interface of the RollingBufferInputStream class.
package com.jenkov.rsync;
import java.io.InputStream;
import java.io.IOException;
public class RollingBufferInputStream {
InputStream source = null;
protected byte[] buffer = null;
protected int start = 0; //current location in buffer.
protected int end = 0; //current limit of data read
//into the buffer
//= next element to read into.
protected int bytesRead = 0;
public RollingBufferInputStream(InputStream source, byte[] buffer) {
this.source = source;
this.buffer = buffer;
}
public byte[] getBuffer() {
return buffer;
}
public int getStart() {
return start;
}
public int getEnd() {
return end;
}
public void moveStart(int noOfBytesToMove){
}
public int availableBytes() {
return this.end - this.start;
}
public boolean hasAvailableBytes(int numberOfBytes) throws IOException {
// if less than numberOfBytes available in buffer,
// method will attempt to fill the buffer,
// so at least numberOfBytes are available...
}
}
The start and end variables mark the start and end indices
in the buffer. The start index progresses as you move the start index down through
the buffer. The end index always marks how many bytes that are read into the buffer.
Filling the Buffer
If the call to hasAvailableBytes() detects that there is not enough
bytes available in the buffer, it will attempt to fill the buffer. Here is the
full hasAvailableBytes() method implementation, so you can see
how it works:
public boolean hasAvailableBytes(int numberOfBytes) throws IOException {
if(! hasAvailableBytesInBuffer(numberOfBytes)){
if(streamHasMoreData()){
if(!bufferHasSpaceFor(numberOfBytes)){
compact();
}
fillDataFromStreamIntoBuffer();
}
}
}
return hasAvailableBytesInBuffer(numberOfBytes);
private boolean hasAvailableBytesInBuffer(int numberOfBytes) {
return (this.end - this.start) >= numberOfBytes;
}
Here is what the method does:
- Checks if the buffer has the required number of bytes available.
- If not, checks if the stream has more data.
- If the stream has more data, checks if the buffer has space for enough data at the bottom, or not.
- If the buffer does not have enough space left, the buffer is compacted.
- The buffer is filled with as much data as possible.
Filling data into the buffer is done by the method fillDataFromStreamIntoBuffer(), which
is shown here:
private void fillDataFromStreamIntoBuffer() throws IOException {
this.bytesRead = this.source.read(this.buffer, this.end,
this.buffer.length - this.end);
this.end += this.bytesRead;
}
As you can see, this method first reads as much data into the buffer as possible, and stores the number of bytes internally. Then it increases the end index with the number of bytes read.
Actually, this method should perhaps read data into the buffer inside a while-loop, so it would continue reading data into the buffer until there was enough bytes in the buffer. Right now it just assumes that a single read will yield enough bytes. You can fix this, if you want.
Compacting the Buffer
Compacting the buffer is done whenever there is not enough space left in the buffer to read in
new data. Whatever data is left in the buffer (between start index and end index) is then moved
to the top of the buffer. The buffer can then be filled at the bottom again. Here is how
the compact() method is implemented:
private void compact() {
int bytesToCopy = end - start;
for(int i=0; i<bytesToCopy; i++){
this.buffer[i] = this.buffer[start + i];
}
this.start = 0;
this.end = bytesToCopy;
}
Full Code Listing
Here is the full code listing for the RollingBufferInputStream:
package com.jenkov.rsync;
import java.io.InputStream;
import java.io.IOException;
public class RollingBufferInputStream {
InputStream source = null;
protected byte[] buffer = null;
protected int start = 0; //current location in buffer.
protected int end = 0; //current limit of data read
//into the buffer
//= next element to read into.
protected int bytesRead = 0;
public RollingBufferInputStream(InputStream source, byte[] buffer) {
this.source = source;
this.buffer = buffer;
}
public byte[] getBuffer() {
return buffer;
}
public int getStart() {
return start;
}
public int getEnd() {
return end;
}
public void moveStart(int noOfBytesToMove){
if(this.start + noOfBytesToMove > this.end){
throw new RuntimeException(
"Attempt to move buffer 'start' beyond 'end'. start= "
+ this.start + ", end: " + this.end + ", bytesToMove: "
+ noOfBytesToMove);
}
this.start += noOfBytesToMove;
}
public int availableBytes() {
return this.end - this.start;
}
public boolean hasAvailableBytes(int numberOfBytes) throws IOException {
if(! hasAvailableBytesInBuffer(numberOfBytes)){
if(streamHasMoreData()){
if(!bufferHasSpaceFor(numberOfBytes)){
compact();
}
fillDataFromStreamIntoBuffer();
}
}
return hasAvailableBytesInBuffer(numberOfBytes);
}
private void fillDataFromStreamIntoBuffer() throws IOException {
this.bytesRead = this.source.read(this.buffer, this.end,
this.buffer.length - this.end);
this.end += this.bytesRead;
}
private void compact() {
int bytesToCopy = end - start;
for(int i=0; i<bytesToCopy; i++){
this.buffer[i] = this.buffer[start + i];
}
this.start = 0;
this.end = bytesToCopy;
}
private boolean bufferHasSpaceFor(int numberOfBytes) {
return (this.buffer.length - this.start) >= numberOfBytes;
}
public boolean streamHasMoreData() {
return this.bytesRead > -1;
}
private boolean hasAvailableBytesInBuffer(int numberOfBytes) {
return (this.end - this.start) >= numberOfBytes;
}
}
| Tweet | |
Jakob Jenkov | |











