Java Web Crawler Implementation
Jakob Jenkov |
Implementing a Java web crawler is a fun and challenging task often given in university programming classes. You may also actually need a Java web crawler in your own applications from time to time. You can also learn a lot about Java networking and multi-threading while implementing a Java web crawler. This tutorial will go through the challenges and design decisions you face when implementing a Java web crawler.
NOTE: THIS TUTORIAL IS STILL IN PROGRESS!
Java Web Crawler Designs
When implementing a web crawler in Java you have a few major design possibilities to choose from. The major design possibilities are:
- Singlethreaded, synchronous crawler
- Multithreaded, concurrent crawler
- Singlethreaded, nio based crawler
- Multithreaded, nio based crawler
Each of these design possibilities can be implemented with extra variations, so that the total number of designs is somewhat larger. I will try to go through all the designs and variations so that you understand them, and why you would use them.
The main design requirements are speed and memory consumption. The speed of the downloading and parsing, and the memory consumption of the parsed documents. Design choices are most often made to increase speed or reduce memory consumption. Of course, the readability and maintainability of the java web crawler code is also an issue.
Singlethreaded, Synchronous Web Crawler
A singlethreaded, synchronous Java web crawler is a simple component. It carries out the following simple actions:
- Download a HTML page from a URL.
- Parse the HTML page.
- Extract needed information from HTML page.
- Extract link URL's from HTML page.
- Repeat from 1 for each URL to crawl.
These actions are illustrated as a time line in this diagram:
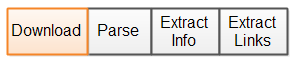 |
| The actions of a singlethreaded Java web crawler shown on a time line. |
The orange time slot is spent downloading the HTML page. The three blue time slots are spent parsing the HTML page and extracting the necessary info and URL's.
Here is a diagram illustrating the time line for crawling multiple pages synchronously:
 |
| Two pages processed by a singlethreaded Java web crawler. |
This fully synchronous design is of course not very efficient. Imagine if the connection to the server which the page is downloaded from is slow. In that case the parsing of the HTML page has to wait a long time before the whole page is downloaded. New pages cannot be downloaded until the first HTML page is fully downloaded, parsed and the links extracted.
Parsing While Downloading
A better design is to parse the HTML page while it is being downloaded, and extract the info and links from the page at the same time. That way, the downloading of the second page may start before the first page is fully downloaded and parsed. This will utilize the bandwidth and CPU of the crawler's computer better. Here is a diagram illustrating that:
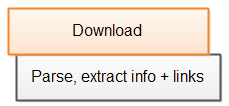 |
| Singlethreaded web crawler parsing the page while it is being downloaded. |
As you can see, the parsing etc. starts as soon as the page starts downloading. It does not wait until the page is fully downloaded. The CPU of the crawling computer is not used much during the download, so it has plenty of extra CPU time (cycles) to parse the page while downloading it.
Additionally, the full HTML page does not have to be downloaded in order to find links in it. Subsequent pages can start downloading as soon as links to them are found in the first page during parsing. Here is a diagram illustrating that:
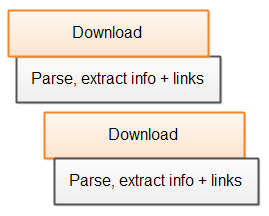 |
| Singlethreaded web crawler parsing multiple pages while they are being downloaded. |
In order to actually implement this design which starts the second download before the first is fully finished, you will need either a singlethreaded NIO based design, or a multithreaded IO based design. I will get into more detail about both possibilities in the following sections.
A NIO Based Java Web Crawler
A Java NIO based web crawler can download multiple pages using a single thread, and parse the pages as they are downloaded.
A Java NIO based web crawler would use NIO's channels and selectors to open connections, and manage multiple open connections using a single thread. Here is a diagram illustrating a Java web crawler design based on NIO:
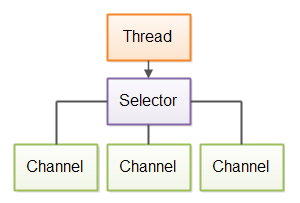 |
| Singlethreaded web crawler based on Java NIO. |
Each open connection (channel) is registered with a selector. The thread polls the selector for channels that have data ready for reading. The thread then reads and processes the data, and polls the selector for the next channel with data ready for reading. Thus a single thread can download multiple pages, and process them.
The data available from a channel (connetion) may not be the full page. It may just be part of the page that is ready for reading. Therefore the thread parsing the data must be able to parse a partial page, and leave the data in a partially parsed state, waiting for when the the rest of the page data arrives. Here is a diagram illustrating that:
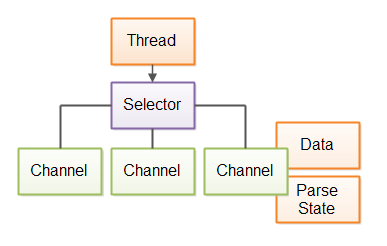 |
| Singlethreaded web crawler based on Java NIO, keeping data and parser state separately for each connection. |
The diagram only shows the data and parser state for a single connection, but it would have to keep data and parser state separately for every connection.
Such a design is not that easy to implement. Keeping track of parser state, and being able to jump in and out of parsing a certain page is not easy to program. Thus, such a design comes at a price: A more complex crawler design.
A simpler NIO based design would be a single thread that downloads multiple pages, but do not start parsing them until the full page is downloaded. But then the CPU and bandwidth is not fully utilized. The parsing of the page does not start until the full page is downloaded, and no new pages can start downloading until parsing starts.
A Multithreaded Java Web Crawler
It is simpler to implement a multithreaded IO based design, in which each thread is only downloading and parsing a single page at a time. That will both utilize the bandwidth and CPU of the crawling computer better than the second NIO based design, and it is easier to implement than the first NIO based design.
Here is a diagram illustrating a multithreaded Java web crawler:
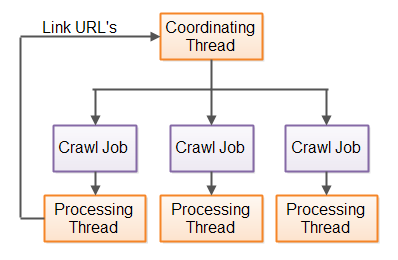 |
| Multihreaded Java web crawler, with a coordinating thread passing URL's to process to worker threads. |
A coordinating thread passes URL's to process to worker threads (processing threads in the diagram). The worker threads download the HTML pages, parse them, and extract information and links from the page. The link URL's are given back to the coordinating thread. The coordinating thread wraps the URL's in a crawl job, and passes the crawl job to a worker thread.
The worker threads are located in a thread pool.
The crawl job object implements either the Runnable or Callable interface,
depending on the concrete design of the crawler.
When each page is downloaded and processed by different threads, then multiple pages can be downloaded and processed at the same time. This utilizes both the bandwidth and CPU better. Neither is idle much time. Both CPU and bandwidth is most of the time used to either download or parse pages.
| Tweet | |
Jakob Jenkov | |











