RSync - Detecting File Differences
Jakob Jenkov |
This text takes a closer look at how exactly how RSync detects differences between to versions of a file.
Like I mentioned in the overview, the old version of the file is split into blocks of, e.g. 1024 or 2048 bytes, and a checksum is calculated for each block.
The new file is then searched byte for byte for blocks with checksums matching those in the old version. Here is a diagram illustrating this process:
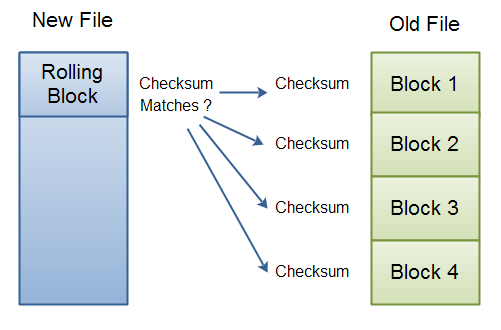 |
| RSync: Block checkums for old file received, and rolling checksum match in new file now begins. |
If you imagine the block size to be 1024 bytes, then this is how it's done:
- Calculate checksum for block, byte 0 to 1023 of file.
-
Is this checksum found in old file?
If no, move file pointer in new file to 1.
If yes, move file pointer in new file to 1024.
Store the information of what block in old file, this block in the new file matched.
- Go back to 1, at the new file position, until a block checksum matches a block checksum in the old file, or you reach end of file.
Repeating these operations on the new version of the file you will iterate through the file byte for byte. During this iteration you will find two types of data in the file:
- Blocks of data that matches blocks in the old file.
- Sequences of bytes that is not part of a matching block.
You have already seen how to detect matching blocks. But, we also need to detect the file differences, and not just the matches. The file differences consist of the unmatching sequences of data left between matching blocks.
For instance, if you have to search to byte 23 in the file before a matching block is found, then the first 22 bytes are considered a difference.
Similarly, if you have just found a matching block, skip to the end of it to search for the next matching block, and have to iterate 16 bytes before you find the next matching block, these 16 bytes are also considered a file difference.
Here is a diagram showing an old file partioned in blocks, and a new version of that file which has been iterated for matching blocks, and unmatching sequences (differences). The numbers on the diagrams represent byte indexes of the blocks and sequences.
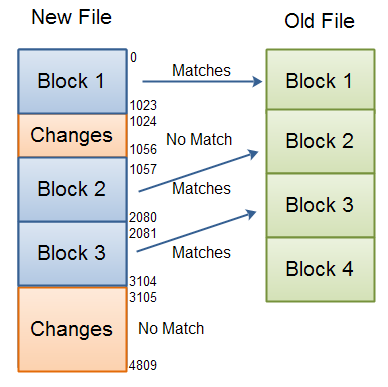 |
| Detecing differences between files using block checksums. |
For the computer keeping the old version of the file to be able to create a new copy which is equal to the new version, this computer needs a list of block references into the old file, and the differences (data), interleaved. More on this later.
| Tweet | |
Jakob Jenkov | |











