RSync - Network Protocol
Jakob Jenkov |
The original RSync document does not discuss the network protocol used by the RSync implementation. However, since this protocol is quite important to the efficiency of RSync, I will discuss it here.
As you know, RSync first calculates the checksums (rolling + hash value) for each block of data in the old version of the file. These checksums needs to be transported to the computer holding the new version of the file, so it can detect the file changes.
Once the differences are detected between the new and old version of the file, the computer holding the old version of the file receives instructions on how to create a copy of the file that is equal to the new version. These instructions consists of references to blocks in the old file which have not changed in the new file, and sequences of changed or new data.
Here is a diagram of what data is send back and forth:
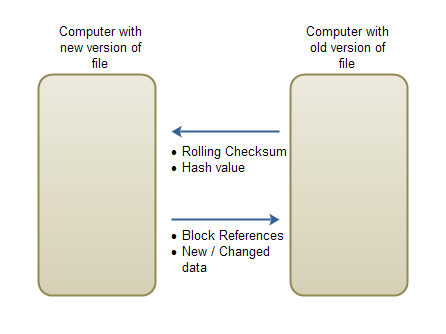 |
| RSync Network Protocol |
Checksum Protocol
In the original RSync implementation the rolling checksum takes up 4 bytes. In my implementation it takes up 8 bytes. The hash value is 16 bytes. That means that for each block of the old version of the file, 24 bytes are sent across the network in this direction. There is no need for any specific block reference number. The computer holding the new version of the file will assume that the first 24 bytes is for block 0, the next 24 bytes for block 1 etc. Here is how the stream looks:
8 bytes rolling checksum - block 0 16 bytes hash value 8 bytes rolling checksum - block 1 16 bytes hash value ... 8 bytes rolling checksum - block N 16 bytes hash value
Merge Instruction Protocol
When sending instructions on how to create a new version of the file, a list of block references are sent along with sequences of new data to insert. A block reference is encoded as a 4-byte int. This makes it possible to reference up to 2,147,483,648 blocks of data.
The data sequences are inserted into the stream of block references, and marked with a negative number as block reference. For instance, a block reference of -1 means that a data sequence is beginning, and it continues until an end code is met.
Here is how the instruction stream could look:
4 byte block reference 4 byte block reference 4 byte block reference 4 byte block reference 4 byte block reference 4 byte sequence begin (-1) N byte data 2 byte sequence end (-1) 4 byte block reference 4 byte block reference 4 byte sequence begin (-1) 4 byte sequence length N byte data 4 byte block reference ...
Protocol Efficiency
When you add the rolling checksum, the hash value and the block reference, you see that a total of 28 bytes are exchanged for every block of data that has not changed. 24 bytes of checksums and a 4 byte block reference. If block size is 1024 bytes, that results in 996 bytes saved per block, compared to sending the whole file across the network = 97.27 % of data saved.
It is possible to optimize the network protocol at the cost of CPU time. There are at least five things you can optimize:
- Size of rolling checksum.
- Size of block references.
- Collapsing of sequential block references.
- Compression of data sequences.
- Storing Checksums Locally
Rolling Checksum Optimization
In the original RSync implementation the rolling checksum consists of two 16 bit values, instead of 2 32 bit values. Cutting the rolling checksum back to 16 bits will increase the number of checksum matches, and thus cost more 16 byte hash value calculations when searching for checksum matches on blocks.
Using a 32 (4 bytes) rolling checksum instead of a 64 bit (8 bytes) will cut down the data exchanged per non-changed block by 4 bytes.
Size of Block References
A block reference of 4 bytes is not necessary in most cases. If block size is 1024 bytes, then here is a list of how big files different block reference byte sizes can reference:
1 byte = 127 * 1024 = 130,048 bytes = 127 KB 2 bytes = 32,768 * 1024 = 33,554,432 bytes = 32 MB 3 bytes = 8,388,608 * 1024 = 8,589,934,592 bytes = 8 GB 4 bytes = 2,147,483,648 * 1024 = 2,199,023,255,552 bytes = 2,048 GB
Remember, the top bit of the block reference is reserved to signal the beginning of a data sequence.
As you can see, most smaller files could be referenced using either 1 or 2 byte references. With a 3 byte reference you can even reference larger video files too. A 4 byte block reference is not necessary unless you have very large files. On average you could probably cut off 2 bytes per block reference. But, it all depends on what kind of files you are synchronizing.
The block reference size could be sent in the beginning of the instruction stream, so that the receiving side knows how large the block references are, before the block references are read from the stream.
Collapsing of Sequential Block References
If you are synchronizing files that do not change much, then the stream of block references will have many block references that are sequential (e.g. 1, 2, 3, 4, 5, 6, 7, 8 etc.). Rather than sending each block reference over separately, you could collapse the block reference, and instead send an interval reference. For instance:
1 2 3 ... 128
Could be transfered as:
1 128
In other words, you only transfer the boundaries of the block reference intervals, for subsequent block references. Of course you need some way to signal that the two block references are indeed interval boundaries, and that the receiving end should interpolate between the two boundary values.
Compressing Data Sequences
The changed data that is sent across as part of the instruction stream, could be compressed to make it take up less bytes. Of course, if you are synchronizing files that are already compressed, like video, MP3, images etc. then this compression would probably not give much, but for non-compressed data there might actually be something to gain.
Storing Checksums Locally
If you know that data synchronzation always happen in one direction, e.g. from your client machine to a server, you can do another little trick.
After synchronizing a file successfully, you can calculate its rolling checksums and hash values and store them locally, on the machine that normally creates the new versions of the file. This has to be done at the time when you know the two versions of the file are equal.
When detecting changes you can compare the changed file against the checksum values of the file before the changes. Doing so saves you the transfer of the 8 byte rolling checksum and the 16 byte hash value, at the expense of a an extra checksum file, stored locally. This checksum file will take up 24 bytes for each 1024 bytes of the original file.
| Tweet | |
Jakob Jenkov | |











