Memory Management for Performance
Jakob Jenkov |
This memory management tutorial explains a set of widely applicable, easily reusable memory management techniques which can potentially boost the performance of your Java application.
In many Java applications a large amount of time is spent reading from and writing to memory. Sometimes a lot of time is even spent just allocating and freeing memory (e.g. instantiating and garbage collecting objects). Simply changing how you read, write, allocate and free memory has an impact on the performance of your application.
Is Java Object Instantiation and Garbage Collection Really Fast?
As Java developers we are often told that:
- Object instantiation is fast
- Garbage collection is fast
It is true that object instantiation and garbage collection tends to get faster with every version of Java. However, in some cases you can still do better by managing these aspects yourself because you can tailor the memory management specifically to how your application uses memory.
Is Java Object Access Fast?
In Java you have no control over where in memory the objects you instantiate are located. As explained in the Modern Hardware tutorial, accessing memory sequentially is faster than accessing it arbitrarily. Thus, accessing collections of objects that are scattered out all over memory is slower than accessing collections of objects that are located next to each other.
Additionally, objects may contain references to other objects (e.g. strings), which will further scatter your objects all over memory.
To get the speedup from sequential memory access you will have to take control of object storage yourself. I will explain some ways to do that later in this tutorial.
This problem may be addressed in Java 10 with value types, but at the time of writing we are just at Java 8.
Memory Management Aspects
Memory management has two aspects:
- Memory allocation and deallocation strategy
- Data structure design
I will get into both of these memory management aspects in the following sections.
Memory Allocation
One problem with Java object allocation is that you have no control over whether the JVM allocates a new object by reclaiming an existing, deallocated object, or whether the JVM allocates that new object in a new location.
Because you cannot control the reuse of previously deallocated objects, you cannot control the maximum memory the JVM will use. Yes, I know about the JVM flags, but they are a workaround - not a solid solution. When you control object allocation, deallocation and reallocation you can make limits like e.g. having a maximum of 10.000 messages in memory at a time. No new message objects are allocated until some a freed. You cannot control memory allocation so fine grained with the JVM flags.
Object Pooling
The obvious solution to take control of your object allocation and deallocation is to use object pools. Yes, I know people say you won't get any speedup, and that you may even lose speed, but I have still to see the benchmark that backs it up. Regardless, without object pooling you cannot control the number of objects allocated, and thereby not control the maximum memory usage.
Object pooling requires that you know when to free the objects again. This may not always be possible to know, since objects may be passed around to many different components, and you may not know in your application which component is the last to use a specific object.
Data Structure Design
When you design data structures you should think about that data which is used together should be located together in memory. This often means that you cannot use objects to represent that data.
An alternative is to use arrays of primitives to represent that data. Instead of having an object contain the
data as fields, you can wrap the primitive arrays in a Navigator object which can access the fields
where they are stored in the primitive arrays.
You can choose two models for primitive arrays:
- Record store
- Column store
Record Store
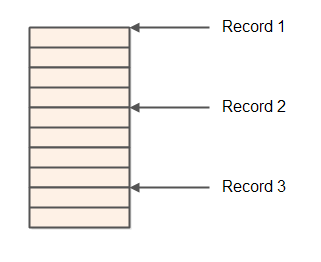
A record store is actually a long byte array with "records" in. Each record consists of several fields which are stored after each other in the byte array. Each field may consist of one or more bytes.
To navigate a record store you need some kind of Navigator component which can navigate from
record to record, and also locate each field within each record.
A record store is good if you need to iterate over the records one at a time and process all its fields. Since all fields of the record are located after each in memory, accessing the fields is fast. Similarly, since all records are located after each other in memory, iterating from record to record is also fast.
A record store is not so good if you need to search in the records based on the contents of a subset of the fields. When you search based on only 1 or 2 of the fields, you have to skip over all the fields that are unused. You are no longer accessing memory as sequentially as you could. For the search use case a column store might be more appropriate.
Column Store
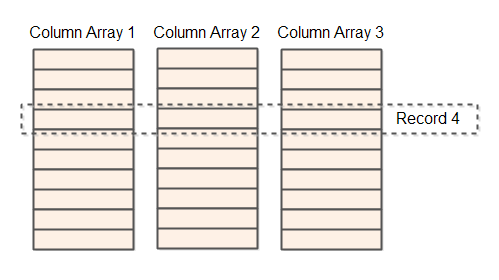
A column store is similar to a record store in that it contains records with fields stored in arrays. But instead of having all fields of the record stored after each other in the same array, a column store uses one array per column (field). That is why it is called a column store.
Using a column store it is very fast to search for records with column values matching a given criteria. You can just scan through the column arrays for the columns you want to search in. This is faster than searching in a record store, since you do not have to skip over unused fields.
The fields of a record is stored with the same index in all the column arrays. That means, that when you have found a column value in a column array that matches the criteria you searched for, you can easily find the value of all other fields for that same record. You just read the value stored at the same index in all the other column arrays.
The column store has the additional advantage that you can use different primitive types for each column. In
the record store you are pretty much forced to use a byte array to make sure you can support all types of fields.
With a column store, one column can be an array of short, int, long etc.
or whatever else you need.
| Tweet | |
Jakob Jenkov | |











