Load Balancing
Jakob Jenkov |
Load balancing is a method for distributing tasks onto multiple computers. For instance, distributing incoming HTTP requests (tasks) for a web application onto multiple web servers. There are a few different ways to implement load balancing. I will explain some common load balancing schemes in this text. Here is a diagram illustrating the basic principle of load balancing:
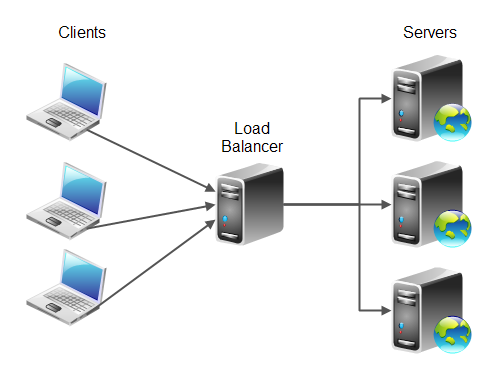
The primary purpose of load balancing is to distribute the work load of an application onto multiple computers, so the application can process a higher work load. Load balancing is a way to scale an application.
A secondary goal of load balancing is often (but not always) to provide redundancy in your application. That is, if one server in a cluster of servers fail, the load balancer can temporarily remove that server from the cluster, and divide the load onto the functioning servers. Having multiple servers help each other in this way is typically called "redundancy". When an error happens and the tasks is moved from the failing server to a functioning server, this is typically called "failover".
A set of servers running the same application in cooperation is typically referred to as a "cluster" of servers. The purpose of a cluster is typically both of the above two mentioned goals: To distribute load onto different servers, and to provide redundancy / failover for each other.
Common Load Balancing Schemes
The most common load balancing schemes are:
- Even Task Distribution Scheme
- Weighted Task Distribution Scheme
- Sticky Session Scheme
- Even Size Task Queue Distribution Scheme
- Autonomous Queue Scheme
Each of these schemes are explained in more detail below.
Even Task Distribution Scheme
An even task distribution scheme means that the tasks are distributed evenly between the servers in the cluster. This scheme is thus very simple. This makes it easier to implement. The even task distribution scheme is also known as "Round Robin", meaning the servers receive work in a round robin fashion (evenly distributed). Here is a diagram illustrating even task distribution load balancing:
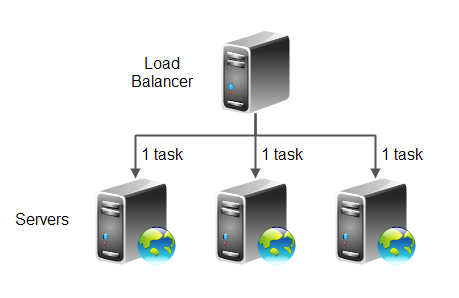
Even task distribution load balancing is suitable when the servers in the cluster all have the same capacity, and the incoming tasks statistically require the same amount of work.
Even task distribution ignores the difference in the work required to process each task. That means, that even if each server is given the same number of tasks, you can have situations where one server has more tasks requiring heavy processing than the others. This may happen due to the randomness of incoming tasks. This would often even itself out over time, since the overloaded server may all of a sudden receive a set of light work load tasks too.
So, even if even task distribution load balancing distributes the tasks evenly onto the servers in the cluster, this may not result in a truly even distribution of the work load.
DNS Based Load Balancing
DNS based load balancing is a simple scheme where you configure your DNS to return different IP addresses to different computers when they request an IP address for your domain name. This achieves an effect that is similar to the even task distribution scheme, except that most computers cache the IP address and thus keep coming back to the same IP address until a new DNS lookup is made.
While DNS based load balancing is possible, it is not the best way of reliably distributing traffic across multiple computers. You are better off using dedicated load balancing software or hardware.
Weighted Task Distribution Scheme
A weighted task distribution load balancing scheme distributes the incoming tasks onto the servers in the cluster using weights. That means that you can specify the weight (ratio) of tasks a server should receive relative to other servers. This is useful if the servers in the cluster do not all have the same capacity.
For instance, if one of three servers only has 2/3 capacity of the two others, you can use
the weights 3, 3, 2. This means that the first server should receive 3 tasks,
the second server 3 tasks, and the last server only 2 tasks, for every 8 tasks received.
That way the server with 2/3 capacity only receives 2/3 tasks compared to the other servers
in the cluster. Here is a diagram illustrating this example:
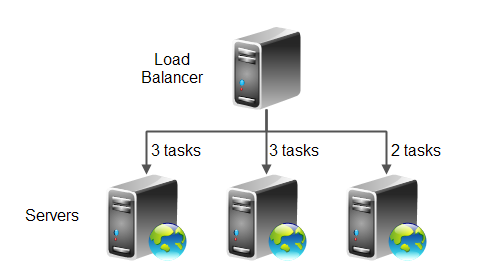
As mentioned earlier, weighted task distribution load balancing is useful when the servers in the cluster do not all have the same capacity. However, weighted task distribution still does not take the work required to process the tasks into consideration.
Sticky Session Scheme
The two previous load balancing schemes are based on the assumption that any incoming task can be processed independently of previously executed tasks. This may not always be the case though.
Imagine if the servers in the cluster keep some kind of session state, like the session object in a Java web application (or in PHP, or ASP). If a task (HTTP request) arrives at server 1, and that results in writing some value to session state, what happens if subsequent requests from the same user are sent to server 2 or server 3? Then that session value might be missing, because it is stored in the memory of server 1. Here is a diagram illustrating the situation:
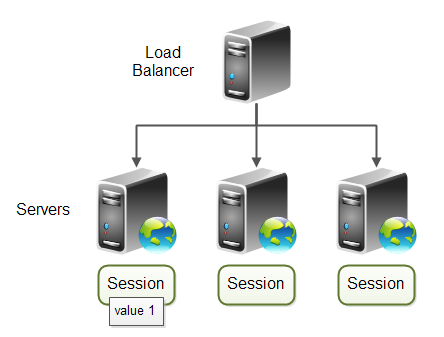
The solution to this problem is called Sticky Session Load Balancing. All tasks (e.g. HTTP requests) belonging to the same session (e.g the same user) are sent to the same server. That way any stored session values that might be needed by subsequent tasks (requests) are available.
With sticky session load balancing it isn't the tasks that are distributed out to the servers, but rather the task sessions. This will of course result in a somewhat more unpredictable distribution of work load, as some sessions will contain few tasks, and other sessions will contain many tasks.
Another solution is to avoid using session variables completely, or to store the session variables in a database or cache server, accessible to all servers in the cluster. I prefer to avoid session variables completely if possible, but you may have good reasons to use session variables.
One way to avoid session variables is by using a RIA GUI + architecture which can contain any needed session scoped variables inside the memory of the RIA client, instead of inside the memory of the web server.
Even Size Task Queue Distribution Scheme
The even size task queue distribution scheme is similar to the weighted task distribution scheme, but with a twist. Instead of blindly distributing the tasks onto the servers in the cluster, the load balancer keeps a task queue for each server. The task queues contain all requests that each server is currently processing, or which are waiting to be processed. Here is a diagram illustrating this principle:
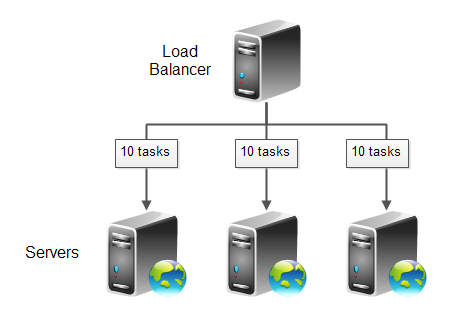
When a server finishes a task, for instance has finished sending back an HTTP response to a client, the task is removed from the task queue for that server.
The even tasks queued distribution scheme works by making sure that each server queue has the same amount of tasks in progress at the same time. Servers with higher capacity will finish tasks faster than servers with low capacity. Thus the task queues of the higher capacity servers will empty faster and thus faster have space for new tasks.
As you can imagine, this load balancing scheme implicitly takes both the work required to process each task and the capacity of each server into consideration. New tasks are sent to the servers with fewest tasks queued up. Tasks are emptied from the queues when they are finished, which means that the time it took to process the task is automatically impacting the size of the queue. Since how fast a task is completed depends on the server capacity, server capacity is automatically taken into consideration too. If a server is temporarily overloaded, its task queue size will become larger than the task queues of the other servers in the cluster. The overloaded server will thus not have new tasks assigned to it until it has worked its queue down.
The load balancer will have to do a bit more accounting using this scheme. It has to keep track of task queues, and it has to keep track of when a task is completed, so it can be removed from the corresponding task queue.
Autonomous Queue Scheme
The autonomous queue load balancing scheme, all incoming tasks are stored in a task queue. The servers in the server cluster connects to this queue and takes the number of tasks they can process. Here is a diagram illustrating this scheme:
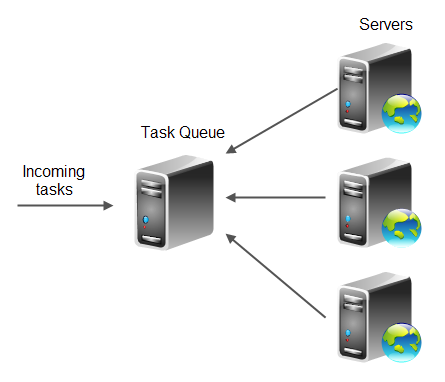
In this scheme there is no real load balancer. Each server takes the load it is able to handle. There is just the task queue and the server. If a server falls out of the cluster, its tasks are kept unprocessed on the task queue, and processed by other servers later. Thus each server functions autonomously of the other servers and of the task queue. No load balancer needs to know what servers are part of the cluster etc. The task queue does not need to know about the servers. Each server just needs to know about the task queue.
Autonomous queue load balancing also implicitly takes the work load and capacity of each sever into consideration. Servers only take tasks from the queue then they have capacity to process them.
Autonomous queue has a little disadvantage compared to even queue size distribution. A server that wants a task needs to first connect to the queue, then download the task, and then provide a response. This is 2 to 3 network roundtrips (depending on whether a response needs to be sent back).
The even queue size distribution scheme has one network roundtrip less. The load balancer sends a request to a server, and the server sends back a response (if needed). That is just 1 to 2 network roundtrips.
Load Balancing Hardware and Software
In many cases you don't have to implement your own load balancer. You can buy ready-made hardware and software for this purpose. Many web server implementations have some kind of built-in software load balancing functionality. Be sure to look at what already exists before you start implementing your own load balancing software!
| Tweet | |
Jakob Jenkov | |











