Event-driven Architecture
Jakob Jenkov |
Event-driven architecture is an architectural style where components in the system emit events and react to events. Instead of component A directly calling component B when some event occurs, component A just emits an event. Component A knows nothing about which components listen for its events.
Event-driven architecture is used both internally within a single process and between processes. For instance, GUI frameworks typically use events a lot. Additionally, the assembly line concurrency model (AKA reactive, non-blocking concurrency model) as explained in my tutorial about concurrency models also uses an event-driven architecture.
In this tutorial I will focus on how event-driven architecture between processes look. Thus, when I write event-driven architecture throughout the rest of this tutorial, that is what I refer to, even if it is not the only meaning of the term.
Event-driven Architecture Between Processes
Event-driven architecture is an architectural style where incoming requests to the system are collected into one or more central event queues. From the event queues the events are forwarded to the backend services that are to process the events.
Event-driven architecture is also sometimes referred to as message-driven architecture or stream processing architecture. The events can be seen as a stream of messages - hence the other two names. The stream processing architecture has also been called a lambda architecture. Regardless, I will continue using the name event-driven architecture.
The Event Queue
I an event-driven architecture you have one or more central event queues into which all events are inserted before they are processed. Here is a simple illustration of event-driven architecture with an event queue:
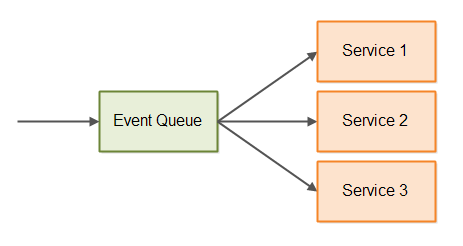
The events are ordered when inserted into the queue so you know in what sequence your system responds to the events.
The Event Log
The messages written to the event queue can be written to an event log (typically on disk). If the system crashes, the system can rebuild its state simply by replaying the event log. Here is an illustration of an event-driven architecture with an event log to persist events:

You can also backup the event log and thus take a backup of the state of the system. You can use this backup to run performance tests on new releases before actually deploying them to production. Or, you could replay the backup of the event log to reproduce some error that has been reported.
Event Collectors
Requests usually arrive over the network, for instance as HTTP requests or via other protocols. The events are received from their many sources via event collectors. Here is an illustration of an event-driven architecture with event collectors added:
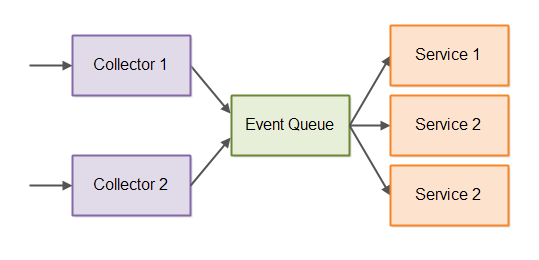
The Reply Queue
Sometimes you may need to send a reply back to a request (event). Therefore some event-driven architectures have a reply queue too. Here is a diagram of an event-driven architecture that uses both an event queue (inbound queue) and a reply queue (outbound queue):
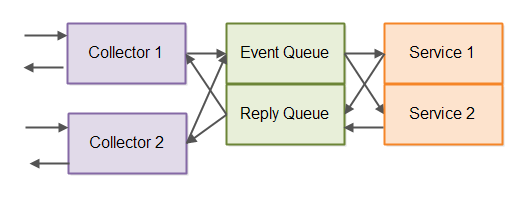
As you can see, the reply may have to be routed back to the correct event collector. For instance, if an HTTP collector (a web server essentially) sends requests received via HTTP into the event queue, the reply generated for that event may have to be sent back to the client via the HTTP collector (server) again.
Normally the reply queue is not persisted, meaning it is not written to the event log. Only the incoming events are persisted to the event log.
Read vs. Write Events
If you categorize all incoming requests as events they will all get pushed into the event queue. If the event queue is persistent (is persisted to an event log) that means that all events are persisted. Persisting events is usually slow, so if we could filter out some of the events that do not need to be persisted, we could potentially increase performance of the event queue.
The reason the event queue is persisted to the event log is so that we can replay the event log and recreate the exact state of the system as caused by the events. To support this, only events that change system state actually need to be persisted. In other words, you can divide the events into read events and write events. Read events only read system state but does not change it. Write events change system state.
With a division of events between read and write events, only write events need to be persisted. This will give a performance increase to the event queue. Exactly how big this performance increase is, depends on the ratio between read and write events.
In order to divide events into read and write events, the distinction must be made already in the event collectors, before the event reaches the event queue. Otherwise the event queue cannot know if a given event should be persisted or not.
You could also split your event queues into two. One event queue for read events and one event queue for write events. That way read events are not slowed down behind slower write events, and the event queue does not have to inspect each message to see if it should be persisted or not. The read event queue does not persist events, and the write event queue always persist events.
Here is an illustration of an event-driven architecture with the event queue split up into read and write event queues:
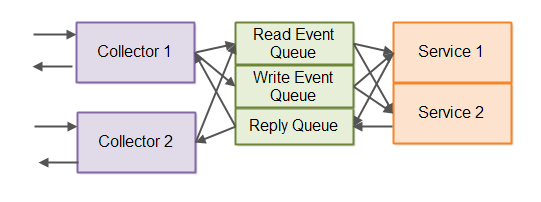
Yes, it looks a bit chaotic with the arrows, but in practice it is not really so chaotic to create 3 queues and distribute messages between them.
Event Log Replay Challenges
The ability to just replay the event log to recreate system state in case of e.g. a system crash or system restart is often emphasized as one of the big advantages of event-driven architecture. In the cases where a log can just be replayed independent of time and surrounding systems, this is a big advantage.
However, replaying the event log completely independent of time is not always possible. I will cover some of the challenges to event log replay in the following sections.
Handling Dynamic Values
As mentioned earlier, write events are events that when processed may change the system state. Sometimes such a state change depends on dynamic values which are resolved at the time the event is processed. Examples of dynamic values could be the date and time the event is processed (e.g. an order date) or the currency exchange rate at that specific date and time.
Such dynamic values represent a challenge to event log replay. If you replay the event log on a different day the service processing the event may resolve a different dynamic value, like another date and time, or another exchange rate. Replaying the event log on a different day would thus not result in recreating the exact same system state as when the events were originally processed.
To solve the problem with dynamic values you could have the write event queue be able to stamp the needed dynamic values into the event. However, for this to work the event queue would need to know what dynamic values each message need. This would complicate the design of the event queue. Every time a new dynamic value is needed, the event queue would need to know how to lookup that dynamic value.
Another solution is that the write event queue only stamps the write events with the date and time of the event. With the original date and time of the event the service processing the event can lookup what the dynamic value was at the given date and time. For instance, it could lookup the exchange rate that was in effect at that time. This of course requires that the service can actually lookup dynamic values based on date and time, and this is not always the case.
Coordination With External Systems
Another challenge to event log replay is coordination with external systems. For instance, imagine that your event log contains product orders from a web shop. When you process an order the first time your system may send the order to an external payment gateway to charge the amount from the customer's credit card.
If you replay the event log later, you do not want the client being charged again for the same order. Thus, you do not want to send the orders to the external payment gateway during replay.
Event Log Replay Solutions
Solving the problems with log replay is not always easy. Some systems have no problems and can replay the event log as it is. Other systems may need to know the date and time of the original event. And yet other systems may need to know a whole lot more - like values obtained from external systems during the original processing of the event.
Replay Mode
In any case, any service listening for events from the write event queue must know whether the incoming event is an original event or a replayed event. That way the service can determine how to handle the resolution of dynamic values and coordination with external systems.
Multi Step Event Queue
Another solution for the event log replay challenges is to have a multi step event queue. Step one collects all write events. Step two resolves dynamic values. Step three coordinates with external systems. In case the log needs to be replayed, only the third step is replayed. Step 1 and 2 are skipped. Exactly how this would be implemented depends on the concrete system.
| Tweet | |
Jakob Jenkov | |











