Joining Data Streams
Jakob Jenkov |
Joining data streams means joining messages from one data stream with the messages or another data stream, often based on keys found inside these messages. Once you start joining data streams, it affects how you can process the streams and how you can scale them. Joining data streams can also affect how much storage is needed to store the messages along the way.
Basic Stream Joining
The basic concept of joining streams means that you read messages from multiple streams and join these messages together. For example, imagine you have one data stream containing update events for customer updates, and another stream containing update events for customer contracts. When you receive an update to a customer, you may want to lookup all the customer's contacts and do something with them. For instance, you might attach the contracts to the customer object and forward that enriched customer object onto another data stream. Or, say the customer's marital status changed from married to single, perhaps you would like to check if their contracts should be changed accordingly.
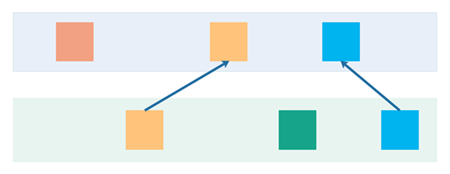
When joining streams the messages in the different streams that are related to each other is typically identified by some set of keys. For example, a customer may have a customer ID and a contract may have a contract ID plus a customer ID (foreign key) of the customer the contract belong to. To join a customer object with its related contract objects, you would lookup the contract objects in the contract stream which have a customer ID referencing the customer ID of the customer in question.
Stream Data Views
When processing a data stream you process one message or record at a time. You do not have access to any previous records in that data stream, and not to any future records either. Thus, in order to be able to locate records from another stream, the messages of that stream must be stored in some kind of data view.
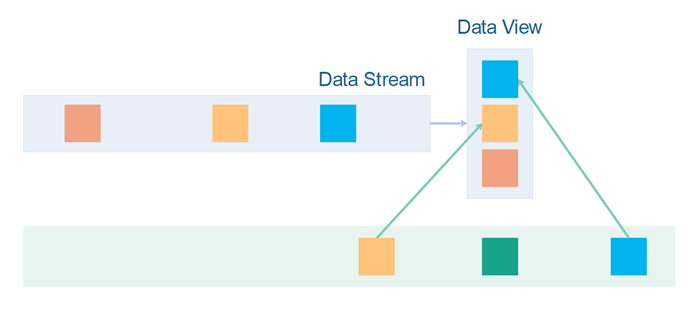
Data views come in two common variations:
- Windows
- Tables
Data Windows
A data window keeps a window of records in which records can be looked up. A data window is typically limited either by time, by number of records or other storage constraints. Time is typically used when it is expected that the records in the two streams are expected to arrive close to each other in time. Then the records in one stream can be stored in a window e.g. 5 minutes or 30 minutes (or whatever time window fits your use case) until the record in the other data stream arrives.
Data Tables
A Data Table keeps records in a tabular data structure. Such a data structure can be a simple key, record map, where records can be looked up by their keys. Records can also be stored with more fields like a database table, so the records can be found both by their primary key, foreign keys and other values.
Combinations of Windows and Tables
Data windows and tables can be combined. A data table can be put together from only a window of records. When a record gets "too old" to be in the window, it is removed from the table again.
Other Data Views
It is also possible to build data views using other data structures like a tree or graph from the records in a data stream or data window. It all depends on what your needs are.
Forwarding Joined Records
Sometimes you may want to forward a record from one data stream which has been joined with a record from another data stream. By forward I mean write the joined record out onto another data stream for someone else to consume. By joined I mean that either the one record has been inserted into the other, or a new record has been created which contains the joined information from both records. Both of these options are illustrated here:
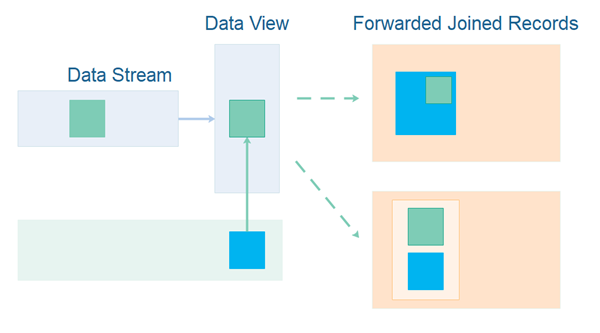
Once you forward joined records, there are a few issues that will affect the correctness and performance of your system. I will get into these issues in the following sections.
Timing Issues
The timing of the arrival of records in the input data streams affect how the joined records look when processed or forwarded. Here is a diagram illustrating how the difference in timing affects the joined record of two input records:
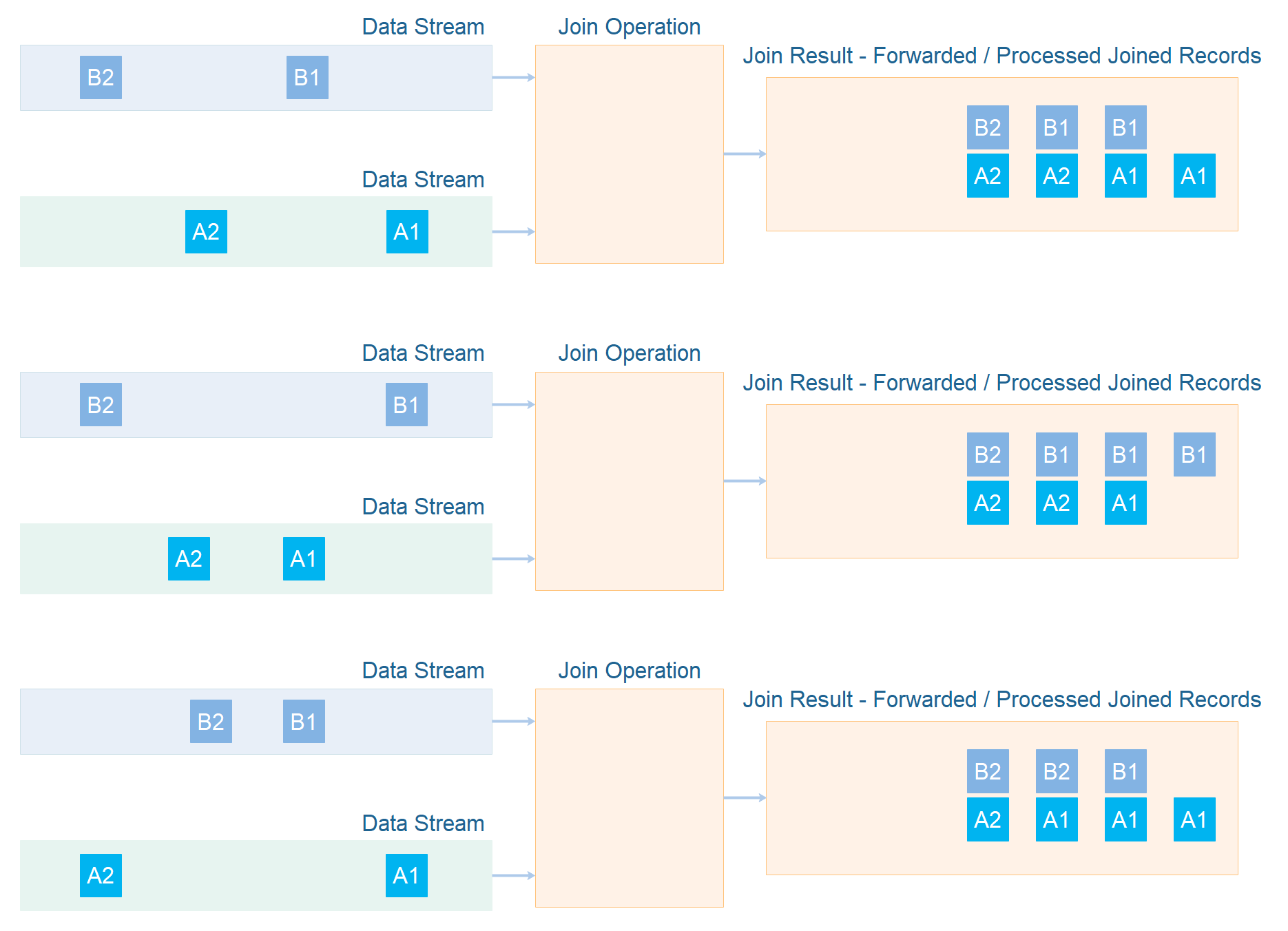
The records A and B are updated 2 times each. These two versions are noted as A1, A2, B1 and B2. The number represents the version of the record. Notice how the timing of the arrival of A1, A2, B1 and B2 affects how the joined record looks when processed or forwarded. The diagram shows 3 different timing permutations, and the joined results look different in each case.
Notice, that even if the final joined records look the same, the joined records leading up to the final record do not. Also, keep in mind that you never know when the "final" record has been joined. There is no way to know what will arrive in the future in the input data streams. Therefore, you cannot just look at the last record in the examples above, and consider that the "final" result of the join operations of those records in the data streams. The "final" result is the full sequence of joined records in all their intermediate mutations.
Horizontal Scalability Issues
If your data streams are scaled horizontally (scaled out), joining records will be somewhat harder. In this section I will try to explain to you why that is.
As mentioned earlier in this tutorial, records that are joined are usually matched by their keys. For instance, a Customer record may have a customerId as primary key, and a Contract record may have a foreign key customerIdFk that references the primary key customerId of the Customer record.
When a data stream is scaled horizontally the records in the data stream are partitioned across different computers. In order to join two records, either the records must be partitioned onto the same computer, or your join operation must know how to lookup a record that is stored on another computer. Both options will be explained in more detail in the following sections.
Record Repartitioning
If your join operation does not know how to lookup records stored on another computer, the records to be joined must be partitioned so that records to be joined are located on the same computer. If this partitioning is not the natural partitioning of the records, then the records in one of the data streams will have to be repartitioned to place records to be joined on the same computer.
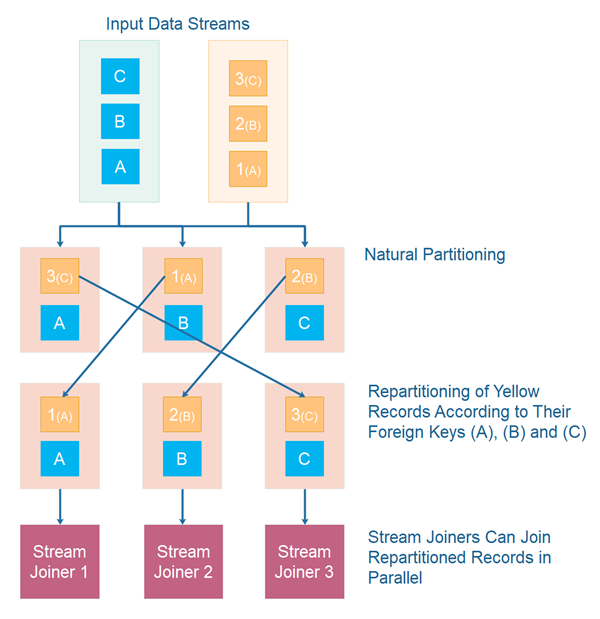
Notice, that repartitioning of records lowers performance of the full record processing chain (AKA graph or topology). Repartitioning also creates an extra copy of the repartitioned records.
Remember, that the data view built up from the records is kept inside the record joiners, and not on the computers containing the raw records (the data streams).
Foreign Key Updates on Joined Records
| Tweet | |
Jakob Jenkov | |











