Data Streaming Scalability
Jakob Jenkov |
Data streaming is a simple, yet powerful mechanism for storing and sharing data in distributed systems. One of the reasons data streams are simple is that they are simple to scale up. Data streams scale very well vertically (increasing computer size), and reasonably well horizontally (adding more computers). In this data streaming scalability tutorial we will look at why data streams scale well vertically, and the options you have available for scaling data streams horizontally. As you will see, when scaled horizontally your stream processing may also have to scale horizontally, and that will affect the design of your stream processing pipeline.
Vertical vs. Horizontal Scaling
To avoid confusing any readers, I will first define vertical and horizontal scaling. Vertical scaling means running your data streaming storage and processors on a more powerful computer. Vertical scaling is also sometimes referred to as scaling up. You scale up the size and speed of its disk, memory, speed of CPUs, possibly CPU cores too, graphics cards etc.
Horizontal scaling means distributing the workload among multiple computers. Thus, the data in the data stream is distributed among multiple computers, and the applications processing the data streams are too (or at least they can be). Horizontal scaling is also sometimes referred to as scaling out. You scale out from a single computer to multiple computers.
Horizontal scaling can be necessary in two situations: First, if it is no longer possible to get a bigger machine with more memory, larger disk etc. that is big enough to hold and process all the data you have. Second, if such a big machine becomes too expensive to upgrade to.
Vertical Scaling
As mentioned above, vertical scaling means scaling up from a less powerful computer to a more powerful computer. The layers of a traditional computer architecture are illustrated here:
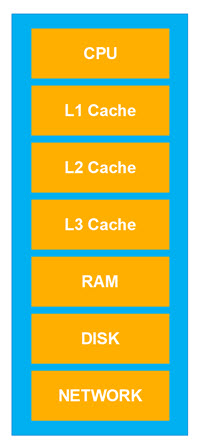
The further away from the CPU data gets, the slower it is for the CPU to access it. In the diagram above, the lower in the stack the data is, the slower it is for the CPU to access.
Each layer in the computer architecture illustrated above is optimized for reading data serially. That means, that reading data which is located sequentially after each other on the disk, in RAM, or in the L3, L2 and L1 caches, is faster than reading data which is spread out randomly throughout DISK, RAM or caches. It is also much faster to write data to disk sequentially, rather than randomly writing to different parts of the disk.
Data streams are exactly serial data structures. They are read serially, and written serially. That means, that you can get data streaming to scale up very well on a single computer. The data written to a stream can be appended to the stream file. Appending to a file is the fastest mode of writing to a file, instead of going back and rewriting parts of the file.
When reading from a file, a big chunk of data is read into RAM. From RAM, a smaller chunk is read into the L3 cache, a smaller chunk into the L2 cache, and an even smaller chunk into the L1 cache from which the CPU can access it. If you only need a little part of the chunks read in from the DISK into RAM, the L3, L2 and L1 caches because your data is spread out all over the disk, then you will need more reads before you have read all your data. When data is located serially, after each other in one big block, it is much faster for the DISK, RAM, L3, L2 and L1 caches to read that data. Quite simply, less read operations are necessary, since the whole chunk read at each step contains relevant data.
Since the reading and writing of data streams utilize modern computers quite well, as you scale up the computer your data streaming services run on, the performance of the data streaming service will scale up almost linearly too.
Horizontal Scaling
As also mentioned earlier in this tutorial, horizontal scaling means scaling your application out onto multiple computers. In data streaming, that would mean distributing the messages in a data stream out onto multiple computers. Here is a diagram illustrating the distribution of messages of a data stream onto multiple computers:
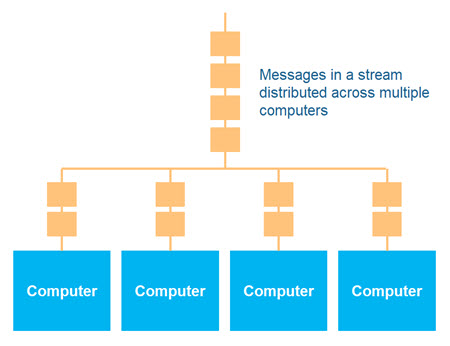
Distributing the messages of a data stream onto multiple computers is also referred to as partitioning the data stream.
Partitioning Affects Message Sequence Guarantee
Partitioning a data stream affects the message sequence guarantee. As long as the messages of a data stream stay on a single machine, you can be guaranteed that the messages are read in the same sequence as they were written. Once you partition a data stream, that guarantee may be affected. In what way the message sequence guarantee is affected depends on the concrete message partitioning method.
Round Robin Partitioning
Round robin data stream partitioning is the simplest way to partition the messages of a data stream across multiple computers. The round robin partitioning method simply distributes the messages evenly and sequentially among the computers. In other words, the first message is stored on the first computer, the second message on the second computer etc. When all computers have received a message from the stream, the round robin method starts from the first computer again.
Using the round robin mechanism is easiest if you only have a single application writing to the data stream. Coordinating round robin across multiple writers is not easy.
When using the round robin data stream partitioning mechanism it is fairly easy for readers of the stream to re-assemble the messages in the stream in the same order they had in the stream before they were partitioned. A reader simply has to read one message from each partition in a round robin fashion.
Key Based Partitioning
Key based partitioning distributes the message across different computers based on a certain key value read from each message. Commonly the identifying id (e.g. primary key) is used as key to distribute the messages. Typically, a hash value is calculated from each key value, and that hash value is then used to map the message to one of the computers in the cluster.
When using key based partitioning, you may lose the overall message sequence guarantee. Messages written to the same computer (same partition) will still hold their sequence in relation to each other, but may lose their place in the overall sequence, as messages written to other computers (other partitions) might get read ahead of them. This is illustrated in the diagram here:
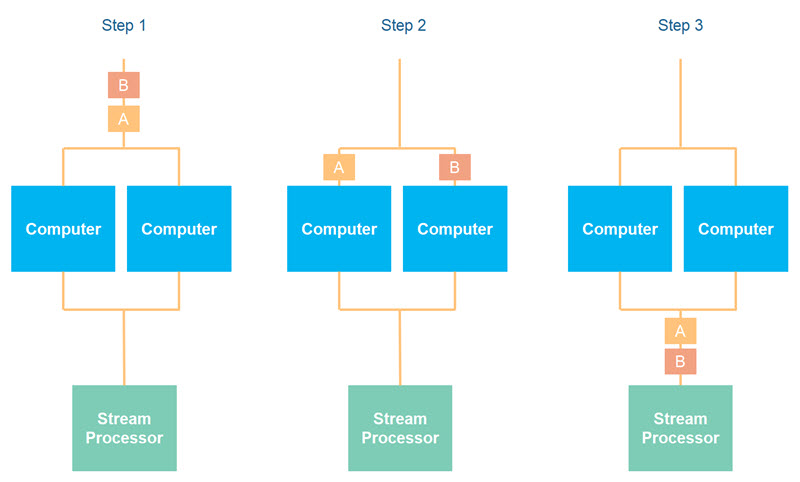
If you are to gain the full benefit of data stream partitioning, you cannot control the sequence in which the stream processor reads from the different partitions. This is even more impractical if you have also scaled up the stream processors, as illustrated here:
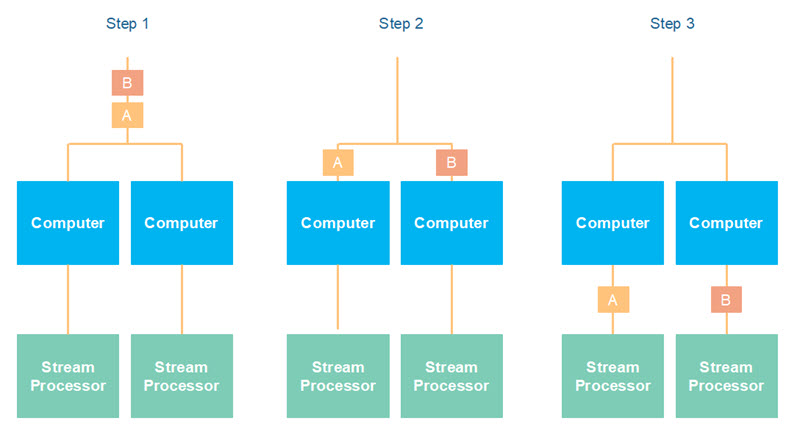
In many cases you do not need a total message sequence guarantee. You only need a message sequence guarantee for related messages in the data stream. For instance, if the messages represents updates to e.g. a customer, then all updates to the same customer should end up on the same computer (partition) in the cluster. That way you can guarantee the sequence of the updates to each customer, which may be good enough for your application. The sequence between updates to different customers may change, but as long as the sequence of updates to the same logical entity (e.g. customer) remains the same, the change of sequence between updates to different logical entities may not necessarily be a problem.
Partitioning messages so that all related messages end up on the same server is often done by partitioning the data on the primary key of the messages. That should guarantee that all messages related to the same logical entity (e.g. same customer) ends up on the same computer.
Using key based partitioning, the messages may not be distributed evenly. It depends on the distribution of the keys, and the hash algorithm used to map a message onto a computer in the cluster. An inappropriate hash algorithm may map more messages onto some computer than onto others. An uneven message distribution will lead to an imperfect load distribution across the computers in the cluster, which again will lead to a suboptimal utilization of the computer resources available.
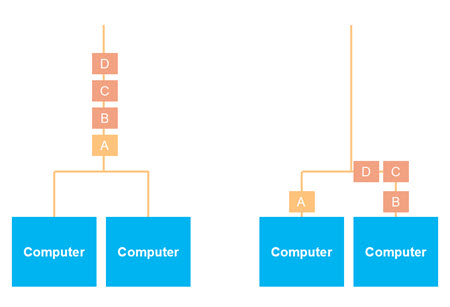
In some cases it makes sense to partition messages based on a non-identifying field value, for instance a foreign key, or some other field value. This will obviously lead to a different distribution of the messages, and may even lead to a quite uneven distribution, for instance if one value used as partitioning key is more prevalent than others.
Here is an illustration of a horizontally scaled data stream with uneven partitioning of the messages across the computers in the cluster:
| Tweet | |
Jakob Jenkov | |











