The Store and Process Stream Processing Design Pattern
Jakob Jenkov |
The store and process stream processing design pattern is a simple, yet very powerful and versatile design for stream processing applications, whether we are talking about simple or advanced stream processing. The pattern scales nicely code-wise from simple stream processing to advanced stream processing, and scales nicely performance-wise too. In this store and process tutorial I will explain how this design pattern works, how to implement it, and how to apply it to a variety of common use cases.
Background
When you look at main stream stream processing API's like Kafka Streams or RxJava, you get the impression that the functional stream processing model is the "way to go" when it comes to stream processing. However, having worked for 15+ months with Kafka Streams I have realized how many limitations the functional stream processing paradigm has. The observer based stream processing pattern has less limitations, but in many cases designing your stream processing application internally using lots of observers and listeners is overkill.
I won't get into too much more detail about the limitations of, and differences between, the functional and observer based stream processing approaches in this tutorial. I want to focus on the store and process pattern. But rest assured that I will document the shortcomings of especially the functional stream processing paradigm in another tutorial in a near future. Developers need to know what problems they are getting themselves into, and why they don't need to mess around with these problems.
The store and process design pattern is a reaction to, and alternative to, the functional / observer based stream processing trend, and although it uses elements from the observer based stream processing paradigm, a store and process design is not a full blown observer based design.
The store and process design pattern is a result of a combination of the research and development within the domain of data streaming engines, processing API's etc. we have carried out at Nanosai, and a long project using Kafka Streams in the data warehouse department of a larger, Scandinavian insurance company.
The Store and Process Design Pattern
The store and process design pattern breaks the processing of an incoming record on a stream into two steps:
- Store the record
- Process the record
These store and process steps are illustrated here:
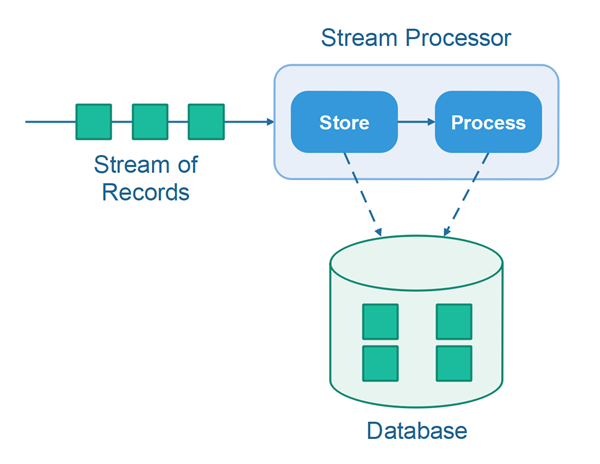
The basic idea is, that first the stream processor will store the record in a database, and then process the record. While processing the record the stream processor can access all records stored in the database. Thus, the record processor can take historic events / records into account during processing.
Store and Process Steps are Both Optional
The store and the process steps are both optional. Sometimes you may need to both store a record and then process it. Other times you may only need to store the record, but not process it. And yet other times you may need only to process the record, but not store it. It depends on the concrete use case, the event / record, timing of events / records etc.
Implementation Template
Implementing a stream processor that follows the store and process design pattern is quite simple. Here is a template for implementing a store and process stream processor:
public class StreamProcessor {
public void onRecord(Record record) {
}
}
Notice how the StreamProcessor class in this template only has a single method. This method
is called for each record in the stream it processes. In case a stream processor is to process messages
from multiple streams, you would have one method per stream. We will look at that in more detail later,
but here is a simple example to give you a mental picture of that model:
public class StreamProcessor {
public void onAdClickRecord(AdClickRecord record) {
}
public void onLandingPageVisitRecord(PageVisitRecord record) {
}
public void onOrderRecord(OrderRecord record) {
}
}
In this example records from all three streams are handled by the same StreamProcessor instance.
However, it is perfectly possible to split the handling of records into multiple processor classes. That depends
on what makes sense in the concrete application.
Batching Stream Records
It is possible to aggregate records up into an array, list or insert them into a database, and when a full batch of records have been aggregated, to process the batch at that time. Aggregating records into a batch is pretty straightforward with the store and process design pattern. The implementation shown below is again just a template, and is thus not complete. But it should be complete enough to give you an idea.
public class StreamProcessor {
private List<AdClickRecord> batch = new ArrayList<>();
private int batchLimit = 1000;
public void onAdClickRecord(AdClickRecord record) {
this.batch.add(record);
if(this.batch.size()) {
processBatch();
}
this.batch.clear();
}
protected void processBatch() {
//... process the batch
}
}
Processing Records From Multiple Streams
Coordinating the processing of records from multiple streams can be challenging. However, the store and process design pattern handles this situation quite well. To show you how the store and process pattern handles the coordinated processing of multiple streams, let's first imagine two streams that need to be processed in concert.
Let's imagine we have a customer stream and an order stream. The customer stream contains records representing
new customers as well as updates to existing customers. The order stream contains records representing new orders,
as well as updates to existing orders. Each order has a customerId referencing the ID of the
customer that made the order.
As the order records stream in, we want to attach the corresponding customer record to each order record. In order to do that, we need to store all incoming customer records in a database. When an order record is received, we can lookup the corresponding customer record in the database and attach it to the order record (or whatever else we need to do with the order-customer pair of records).
Here is an illustration of how the store and process design pattern looks when processing records from multiple streams:
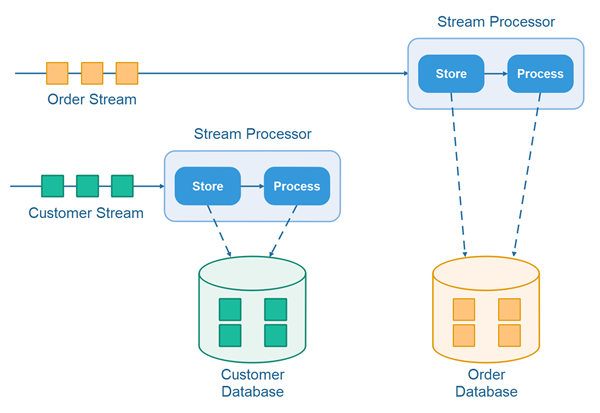
Note: The records from the different streams do not necessarily have to be stored in different databases. They can also be stored in different tables within the same database.
Implementation Template - Multiple Streams
The earlier implementation template hinted at how to design a stream processor to handle records from multiple streams, but let me just show you a draft again, to make the idea clearer:
public class StreamProcessor {
private OrderDao orderDao = null;
private CustomerDao orderDao = null;
public StreamProcessor(OrderDao orderDao, CustomerDao customerDao) {
this.orderDao = orderDao;
this.customerDao = customerDao;
}
public void onOrderRecord(OrderRecord orderRecord) {
this.orderDao.insertOrder(orderRecord);
CustomerRecord customer =
this.customerDao.readCustomer(orderRecord.getCustomerId());
//process order with customer hereafter.
}
public void onCustomerRecord(CustomerRecord record) {
this.customerDao.insertCustomer(record);
//process customer hereafter.
}
}
Obviously you will need to make modifications to this template. For instance, if order and customer records can represent updates to existing orders and customers, you will probably have to merge the records into the database rather than just insert them (merge = insert if not exists, update if exists).
Handling Out of Order Record Arrival
One of the issues you need to take into consideration when processing records from multiple streams in concert is, the possibility for out of order arrival of records.
For instance, in the example mentioned above, what happens if an order record arrives and there is no matching customer record for it, because that customer record has not arrived yet? Then we cannot attach the customer record to the order record.
The solution is, to store order records without a matching customer record in the database without processing them. When the matching customer records arrives later on, you check the order database if there are any order records waiting for this customer. If there are, you process all the waiting order records at that time. The late arrived customer record is of course stored too, for matching against future order records.
Here is an illustration of how the store and process pattern looks when processing records from multiple streams in coordination:
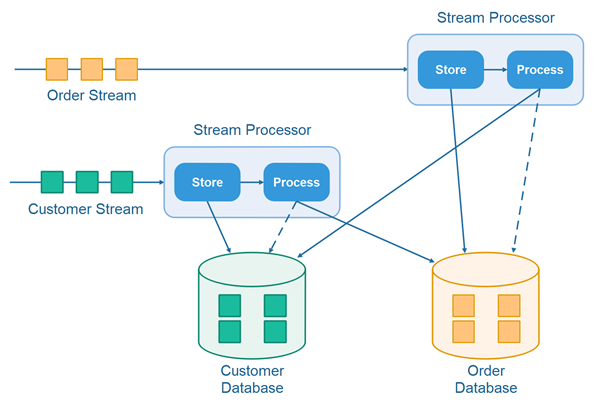
When order records arrive, the processor checks the customer database for a matching customer record. Similarly, when the customer records arrive, the processor checks the order database for waiting order records. If any waiting order records are found, they are matched with the newly arrived customer, and the waiting records can be deleted (or be marked as "processed").
This solution scales nicely to more than 2 streams, by the way.
Implementation Template - Out of Order Handling
Here is a simple implementation template for out-of-order handling using a store and process design:
public class StreamProcessor {
private OrderDao orderDao = null;
private CustomerDao orderDao = null;
public StreamProcessor(OrderDao orderDao, CustomerDao customerDao) {
this.orderDao = orderDao;
this.customerDao = customerDao;
}
public void onOrderRecord(OrderRecord orderRecord) {
this.orderDao.insertOrder(orderRecord);
CustomerRecord customer =
this.customerDao.readCustomer(orderRecord.getCustomerId());
if(customer != null) {
// process order with customer hereafter.
} else {
// leave order in database for when matching customer arrives
}
}
public void onCustomerRecord(CustomerRecord record) {
this.customerDao.insertCustomer(record);
//process customer hereafter.
// lookup any unprocessed orders in database for this customer.
// if any unprocessed orders found, process them with newly arrived customer
List<OrderRecord> unprocessedOrders =
this.orderDao.readUnprocessedOrdersForCustomer(customer.getId());
// process orders, and mark them as processed in the database.
}
}
Caching
To increase performance you can cache records from the databases in in-memory data structures like hashtables, lists, trees etc. When storing a record in a database the corresponding caches will have to be updated too. When looking up records they can be looked up in the cache. If not found in the cache, the database can be queried for the record. The caches can speed up record processing quite significantly.
Data Debugging
Having the records stored in a database makes it a lot easier to debug what records you have processed, see the latest version of a record, join records between tables, check if you actually have received all the data you expected to receive etc. - in case you discover errors in your pipeline. A stream processing pipeline is otherwise quite opaque, as records only exist in it for a short instance while being processed.
Having database storage enabled during development and testing can be quite handy - even if you don't need the database in a production setting.
| Tweet | |
Jakob Jenkov | |











