HTML and URLs
Jakob Jenkov |
Every HTML document which is accessible via the web, is located at some URL. The word URL is short for Uniform Resource Locator. The URL is the "address" on the web of the HTML document.
URLs as Addresses of Resources
In fact it is not just HTML documents that have URL's. Any file accessible via the web has a URL, including images, JavaScripts, CSS style sheet files, Flash files etc. All these files are called resources. Even dynamically generated files of data have a URL.
When you want to view a HTML document in a browser, you type in the URL of the document into the browsers address bar.
Here is an example URL:
http://www.jenkov.com/books/jquery/index.html
This URL consists of three parts:
- Protocol
- Domain
- Resource path
All three parts are illustrated here:
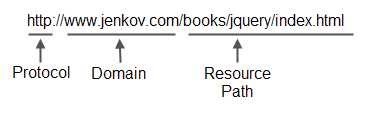 |
| A URL consists of a protocol name, domain name, and resource path. |
The protocol tells what protocol is needed to access the resource the URL points to.
Typically the protocol is either http or https.
The domain is a name that is translated into an IP address. Thus, the domain name really points to a server
somewhere on the internet. This is the server hosting the resource. In the example above the domain
is www.jenkov.com .
The resource path is the location of the resource within the server the resource is hosted on.
In the example above, the resource path is /books/jquery/index.html . The resource
path can be thought of as a logical directory structure. In the example above, the resource path
contains two logical directories: books and jquery.
Query String
A URL can contain a query string. Here is an example:
http://www.jenkov.com/books/jquery/index.html?param1=value1¶m2=value2
The query string part of the above URL is:
?param1=value1¶m2=value2
The query string starts with a ? character, and then comes one or more name=value
pairs. Each pair is separated by an & character. In the example above the query string contains
two name=value pairs. The param1=value1 and the param2=value2.
The name of a name=value pair is the name of a parameter passed to the server where the
resource is hosted. The value is the value of the parameter named by the name.
It is up to the server how it interprets the query string, and whether a query string is needed at all to access a given resource. If a resource does not need a query string in its URL, but you add one anyways, the server typically just ignores the query string.
Fragment Identifier
A URL can contain a fragment identifier. A fragment identifier points to (identifies) a fragment of the HTML document the URL points to. Fragments are typically only used in HTML documents. Using a fragment identifier in the URL you can point not only to the HTML document itself, but to a location inside the HTML document. This is covered in more detail in the text about links.
Here is an example of a URL with a fragment identifier:
http://www.jenkov.com/books/jquery/index.html#someFragmentId
The fragment identifier is appended after the # character. Thus, the fragment
identifier in the example above is someFragmentId.
The fragment identifier has to point to a fragment ID in the target HTML document. How to insert that, is explained in the text on links.
A URL can consist of just the fragment identifier. Here is an example:
#someFragmentId
In that case the URL is interpreted as pointing to a fragment ID inside the same document as the URL is contained in.
In case a URL has a query string appended to it, the fragment identifier is appended after the query string. Here is an example URL with both query string and fragment identifier:
http://www.jenkov.com/books/jquery/index.html?param1=value1¶m2=value2#someFragmentId
Relative URLs
A URL can be relative. A relative URL consists of just the resource path itself.
A relative URL is interpreted relative to the URL of the HTML document that contains the URL. Thus, if the URL of the HTML document containing the URL is:
http://jenkov.com/books/jquery/index.html
then all relative URL's inside that HTML document are intepreted as being relative to that URL.
A relative URL containing just a document name, e.g. html-book.html is interpreted
as being located in the same logical directory as the /books/jquery/index.html
page. That means in the logical directory /books/jquery. The full resource path
will be interpreted as:
/books/jquery/html-book.html
The protocol and domain name is also interpreted as being the same as the document containing the
relative URL. Thus, the resource path /books/jquery/html-book.html is interpreted
to be located at the URL:
http://jenkov.com/books/jquery/html-book.html.
You can use two dots (..) to signal that the relative URL points one directory up
from the resource path of the document containing the URL. Thus, this relative URL
../html4/html-book.html
found inside a HTML document at the resource path /books/jquery/index.html, will
be interpreted as the resource path:
/books/html4/html-book.html
Notice how the directory jquery is cut off the resource path, before the rest of the
relative URL is appended to it.
The full URL will be interpreted as:
http://jenkov.com/books/html4/index.html
You can use multiple dots (..) separated by a slash character (/) if you want
the relative URL to go up more than one logical directory. Thus, the relative URL
../../html-book.html
inside a document located at resource path /books/jquery/index.html, will be interpreted
as:
/html-book.html
Notice how both the books and jquery logical directory path is cut off the
documents URL, before the rest of the relative URL is appended to it.
The full URL will be interpreted as:
http://jenkov.com/html-book.html
A relative URL that starts with the slash (/) character is always interpreted as
being relative to the root of the logical directory hierarchy, instead of to the URL of the document
containing it.
Here is an example of a URL that is relative to the root of the logical directory structure:
/books/jquery/index.html
It doesn't matter what the URL is of the HTML document containing this URL, it will always be interpreted the same - as relative to the root of the logical directory hierarchy.
The Advantage of Relative URL's
It can be an advantage to link internally between pages in your website using relative URL's instead of full URL's including protocol and domain name.
Often when you develop a website on your local machine, the web server
is running on the URL http://localhost:8080. If you use a full URL in your links and URL's,
you will need to search and replace all URL's before putting the website online, on e.g. a domain
like jenkov.com.
Using relative URL's, though, the URL's will be interpreted as being either relative to http://localhost:8080
or your websites domain (e.g. http://jenkov.com), depending on where you access the website.
This makes development a lot easier, since you don't have to change URL's before uploading the website to the web server.
| Tweet | |
Jakob Jenkov | |











