Java ForkJoinPool
Jakob Jenkov |
The Java ForkJoinPool was added to Java in Java 7. The ForkJoinPool is similar to the
Java ExecutorService but with one difference: The Java ForkJoinPool
makes it easy for tasks to split their work up into smaller tasks which are then submitted to the
ForkJoinPool too. Tasks can keep splitting their work into smaller subtasks for as long as it makes sense
to further subdivide the task. It may sound a bit abstract, so in this fork and join tutorial I will explain how the
Java ForkJoinPool works, and how splitting tasks up work.
Java ForkJoinPool Tutorial Video
If you prefer video, I have a video version of this Java ForkJoinPool tutorial here:

Fork and Join Explained
Before we look at the ForkJoinPool I want to explain how the fork and join principle works
in general.
The fork and join principle consists of two steps which are performed recursively. These two steps are the fork step and the join step.
Fork
A task that uses the fork and join principle can fork (split) itself into smaller subtasks which can be executed concurrently. This is illustrated in the diagram below:
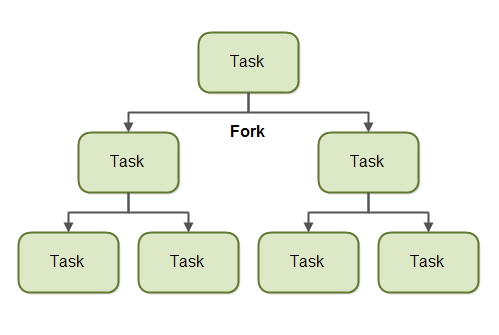
By splitting itself up into subtasks, each subtask can be executed in parallel by different CPUs, or different threads on the same CPU.
A task only splits itself up into subtasks if the work the task was given is large enough for this to make sense. There is an overhead to splitting up a task into subtasks, so for small amounts of work this overhead may be greater than the speedup achieved by executing subtasks concurrently.
The limit for when it makes sense to fork a task into subtasks is also called a threshold. It is up to each task to decide on a sensible threshold. It depends very much on the kind of work being done.
Join
When a task has split itself up into subtasks, the task waits until its subtasks have finished executing.
Once its subtasks have finished executing, the task may join (merge) all the results into one result. This is illustrated in the diagram below:
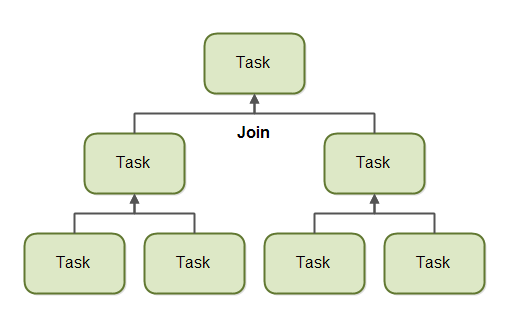
Of course, not all types of tasks may return a result. If the tasks do not return a result then a task just waits for its subtasks to complete. No result merging takes place then.
The Java ForkJoinPool
The Java ForkJoinPool is a special thread pool which is designed to work well with fork-and-join task splitting.
The ForkJoinPool class is located in the java.util.concurrent package, so the full class name is
java.util.concurrent.ForkJoinPool.
Creating a ForkJoinPool
You can create a Java ForkJoinPool in 2 ways. Either via the ForkJoinPool constructor, or via a static factory method in the ForkJoinPool class.
Let's first see how to create a Java ForkJoinPool using its constructor. As a parameter to the ForkJoinPool
constructor you pass the indicated level of parallelism you desire. The parallelism level indicates how many
threads or CPUs you want to work concurrently on tasks passed to the ForkJoinPool.
Here is a Java ForkJoinPool creation example:
ForkJoinPool forkJoinPool = new ForkJoinPool(4);
This example creates a ForkJoinPool with a parallelism level of 4.
You can also use the static factory method ForkJoinPool.commonPool(). This returns the shared ForkJoinPool instance. This common ForkJoinPool will have a parallelism level defined internally (according to the workload submitted to it - as far as I understand).
If you need to use ForkJoinPool instances in several places in your application, it might be a better idea to just use the shared common ForkJoinPool, rather than creating your own. That way you might share the underlying hardware better, than if you create multiple ForkJoinPool instances yourself and try to match their parallelism to the underlying hardware yourself.
Here is how you create a Java ForkJoinPool using the static factory method commonPool():
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
Submitting Tasks to the ForkJoinPool
You submit tasks to a ForkJoinPool similarly to how you submit tasks to an ExecutorService.
You can submit two types of tasks. A task that does not return any result (an "action"), and a task which does
return a result (a "task"). These two types of tasks are represented by the RecursiveAction and
RecursiveTask classes. How to use both of these tasks and how to submit them will be covered in the
following sections.
Both the RecursiveAction and the RecursiveTask classes are subclasses of the ForkJoinTask class, by the way.
RecursiveAction
A RecursiveAction is a task which does not return any value. It just does some work, e.g. writing
data to disk, and then exits.
A RecursiveAction may still need to break up its work into smaller chunks which can be executed by
independent threads or CPUs.
You implement a RecursiveAction by subclassing it. Here is a RecursiveAction example:
import java.util.concurrent.RecursiveAction;
public class MyRecursiveAction extends RecursiveAction {
private long workLoad = 0;
public MyRecursiveAction(long workLoad) {
this.workLoad = workLoad;
}
@Override
protected void compute() {
//if work is above threshold, break tasks up into smaller tasks
if(this.workLoad > 16) {
System.out.println("Splitting workLoad : " + this.workLoad);
long workload1 = this.workLoad / 2;
long workload2 = this.workLoad - workload1;
MyRecursiveAction subtask1 = new MyRecursiveAction(workload1);
MyRecursiveAction subtask2 = new MyRecursiveAction(workload2);
subtask1.fork();
subtask2.fork();
} else {
System.out.println("Doing workLoad myself: " + this.workLoad);
}
}
}
This example is very simplified. The MyRecursiveAction simply takes a fictive workLoad
as parameter to its constructor. If the workLoad is above a certain threshold, the work is split
into subtasks which are also scheduled for execution (via the .fork() method of the subtasks.
If the workLoad is below a certain threshold then
the work is carried out by the MyRecursiveAction itself.
You can schedule a MyRecursiveAction for execution with a Java ForkJoinPool like this:
MyRecursiveAction myRecursiveAction = new MyRecursiveAction(24); forkJoinPool.invoke(myRecursiveAction);
RecursiveTask
A RecursiveTask is a task that returns a result. It may split its work up into smaller tasks, and
merge the result of these smaller tasks into a collective result. The splitting and merging may take place on
several levels. Here is a RecursiveTask example:
import java.util.concurrent.RecursiveTask;
public class MyRecursiveTask extends RecursiveTask<Long> {
private long workLoad = 0;
public MyRecursiveTask(long workLoad) {
this.workLoad = workLoad;
}
protected Long compute() {
//if work is above threshold, break tasks up into smaller tasks
if(this.workLoad > 16) {
System.out.println("Splitting workLoad : " + this.workLoad);
long workload1 = this.workLoad / 2;
long workload2 = this.workLoad - workload1;
MyRecursiveTask subtask1 = new MyRecursiveTask(workload1);
MyRecursiveTask subtask2 = new MyRecursiveTask(workload2);
subtask1.fork();
subtask2.fork();
long result = 0;
result += subtask1.join();
result += subtask2.join();
return result;
} else {
System.out.println("Doing workLoad myself: " + this.workLoad);
return workLoad * 3;
}
}
}
This example is similar to the RecursiveAction example except it returns a result. The class
MyRecursiveTask extends RecursiveTask<Long> which means that the result returned
from the task is a Long .
The MyRecursiveTask example also breaks the work down into subtasks, and schedules these subtasks
for execution using their fork() method.
Additionally, this example then receives the result returned by each subtask by calling the join()
method of each subtask. The subtask results are merged into a bigger result which is then returned. This kind
of joining / mergining of subtask results may occur recursively for several levels of recursion.
You can schedule a RecursiveTask like this:
MyRecursiveTask myRecursiveTask = new MyRecursiveTask(128);
long mergedResult = forkJoinPool.invoke(myRecursiveTask);
System.out.println("mergedResult = " + mergedResult);
Notice how you get the final result out from the ForkJoinPool.invoke() method call.
| Tweet | |
Jakob Jenkov | |











